The mDOT Center
Transforming health and wellness via temporally-precise mHealth interventions






mDOT@MD2K.org
901.678.1526
901.678.1526


Abstract Cardiac Rehabilitation (CR) programs effectively improve cardiovascular outcomes by helping patients adopt heart-healthy lifestyles. However, up to 50% of patients stop exercising or following a healthy diet within months after completing CR, causing many gains to be lost. mHealth offers promising ongoing support after CR, helping patients sustain and enhance their health improvements. Yet, to fulfill this potential, new approaches are needed to boost engagement in mHealth interventions. Patients often abandon these programs due to discouragement from unmet goals, frustration with poorly timed or excessive messaging, or competing life demands. Once abandoned, mHealth interventions lose their ability to support patients further. This project addresses this problem by developing novel algorithms and user interfaces – components that let users interact with the mHealth app – that enable interventions to adapt effectively to changing individual needs and priorities, ensuring sustained usefulness and support over time. The methods will (1) improve intervention delivery by monitoring and optimizing both intermediate behavioral outcomes like physical activity commitment and user engagement, and (2) empower users to adjust intervention behavior by reviewing and correcting the data guiding decision-making, and by specifying support levels that better fit their current circumstances. After developing and optimizing these innovations in a micro-randomized trial with 60 CR patients, we will evaluate their impact on engagement and physical activity in a 9-month randomized controlled trial with 150 CR patients. This trial will compare an intervention with the new adaptive algorithms and interfaces to one with similar behavior change components but without these adaptive features. If successful, this work will enable a new generation of mHealth interventions capable of effectively supporting sustained behavior change for cardiovascular risk reduction and other health domains.
The collaboration creates scalable, adaptive mHealth tools that improve sustained behavior change not just in cardiovascular health but across multiple health domains, making interventions more personalized, effective, and impactful in long term chronic care support.
This collaborator, Klasnja, and his previous CP played a central role in TR&D2’s development of adaptive intervention methods, particularly in analyzing MRT data and advancing RL algorithms. Early work together produced several papers on binary outcome analysis, flexible modeling, and off-policy RL, with multiple pieces highlighted by journal editors. Weekly meetings between investigators and students from both teams fostered deep integration across behavioral theory, causal modeling, and algorithm design. Notably, the CP co-led the development of the pJITAI toolbox, now in user testing, and collaborated on new hierarchical Thompson sampling algorithms and resampling methods to evaluate RL performance. Joint work has continued with ongoing publications and tool deployment efforts alongside other CPs.
The collaboration creates scalable, adaptive mHealth tools that improve sustained behavior change not just in cardiovascular health but across multiple health domains, making interventions more personalized, effective, and impactful in long term chronic care support.
TR&D2 is collaborating with CP13 on the construction of the domain science-informed causal directed acyclic graphs (DAGs) and their use for RL algorithm development. This collaboration i impacts data collection in CP13’s upcoming micro-randomized trial (with attention to obtaining the needed variables on the DAG). Further TR&D2 is collaborating on guardrails on the frequency that burdensome queries for information can be made, and TR&D1 Aim 1 is collaborating on a risk score for physical inactivity.
Most recently CP13 has motivated TR&D2 to consider how DAGs can be used to speed up learning by an RL algorithm (TR&D2 Aim 1 in this renewal). Further CP13 is motivating TR&D2 to consider how best to learn the effects of RL “actions” that include burdensome queries for information. An early-stage theoretical paper has resulted due to the former motivation and a second early-stage theoretical paper is underway due the latter motivation. CP13 has challenged TR&D1 Aim 3 to develop methods for synthesizing audio interventions for delivery via a novel hearable platform, a smart ear bud capable of audio messaging.
The collaboration creates scalable, adaptive mHealth tools that improve sustained behavior change in cardiovascular health and other health domains, making interventions more personalized, effective, and impactful in long term chronic care support, and supports the use of emerging hearable platforms.




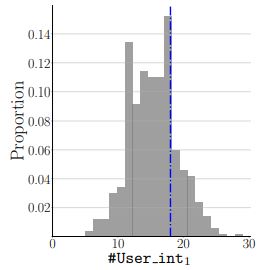
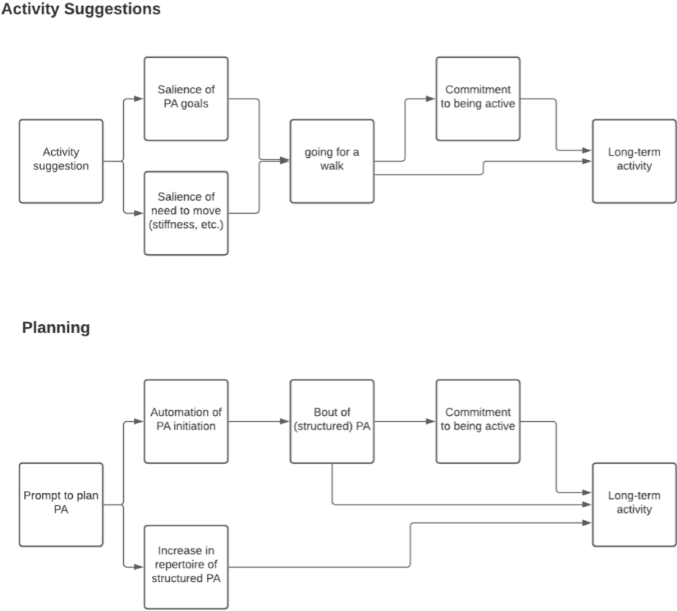


CP, Heart Disease, Physical Activity, TR&D1, TR&D2, TR&D3
You must be logged in to post a comment.
No Comments