
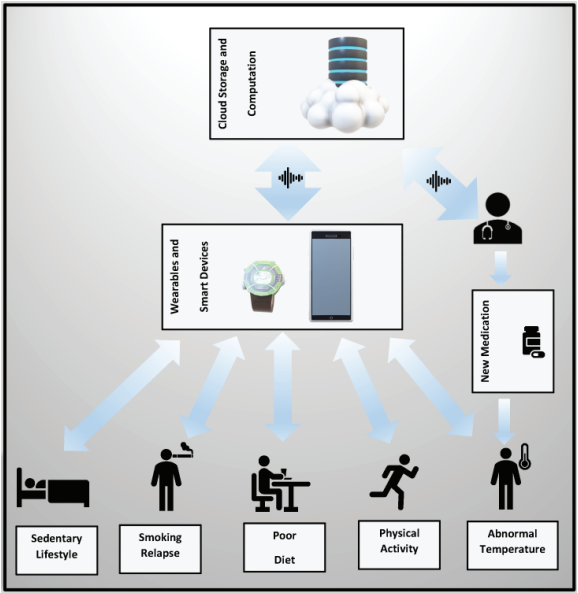
CP 1: Novel Use of mHealth Data to Identify States of Vulnerability and Receptivity to JITAIs
CP / Smoking Cessation / TR&D1 / TR&D2 / TR&D3







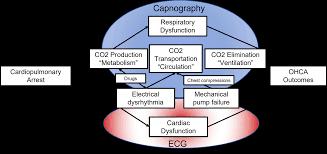
Nassal, M. Sugavanam, N., Aramendi, E., Jaureguibeitia, X., Elola, A., Panchal, A., Ulintz, A., Wang, H., Ertin, E.
Proceedings of the 57th Annual Hawaii International Conference on System Sciences, HICSS 2024
January 3, 2024
Artificial Intelligence (AI), cardiac arrest, resuscitation, end tidal capnography, reinforcement learning
Artificial Intelligence (AI) and machine learning have advanced healthcare by defining relationships in complex conditions. Out-of-hospital cardiac arrest (OHCA) is a medically complex condition with several etiologies. Survival for OHCA has remained static at 10% for decades in the United States. Treatment of OHCA requires the coordination of numerous interventions, including the delivery of multiple medications. Current resuscitation algorithms follow a single strict pathway, regardless of fluctuating cardiac physiology. OHCA resuscitation requires a real-time biomarker that can guide interventions to improve outcomes. End tidal capnography (ETCO2) is commonly implemented by emergency medical services professionals in resuscitation and can serve as an ideal biomarker for resuscitation. However, there are no effective conceptual frameworks utilizing the continuous ETCO2 data. In this manuscript, we detail a conceptual framework using AI and machine learning techniques to leverage ETCO2 in guided resuscitation.
This publication proposes a conceptual framework for utilizing Artificial Intelligence (AI) and machine learning to create End Tidal Capnography (ETCO2) guided resuscitation for Out-of-Hospital Cardiac Arrest (OHCA). The aim is to move beyond rigid, fixed-interval resuscitation algorithms by leveraging continuous ETCO2 data as a real-time biomarker, alongside other physiological measurements, to develop personalized, dynamic interventions that are responsive to a patient’s evolving cardiac physiology. This approach seeks to improve the currently static survival rates for OHCA by enabling a deeper analysis of ETCO2 trends in relation to patient characteristics and interventions, potentially revealing “hidden” patterns and allowing for reward-based algorithms to guide optimal treatment strategies.
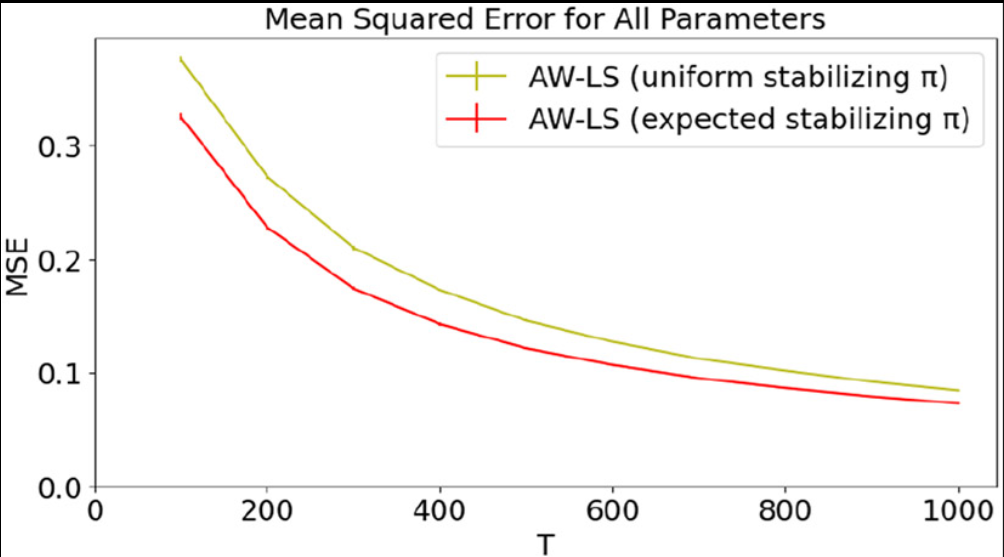
Advances in Neural Information Processing Systems
December 2021
contextual bandit algorithms, confidence intervals, adaptively collected data, causal inference
We develop theory justifying the use of M-estimators—which includes estimators based on empirical risk minimization as well as maximum likelihood—on data collected with adaptive algorithms, including (contextual) bandit algorithms.
Conference on Innovative Applications of Artificial Intelligence (IAAI 2023)
February 7, 2023
reinforcement learning, online learning, mobile health, algorithm design, algorithm evaluation
Dental disease is one of the most common chronic diseases despite being largely preventable. However, professional advice on optimal oral hygiene practices is often forgotten or abandoned by patients. Therefore patients may benefit from timely and personalized encouragement to engage in oral self-care behaviors. In this paper, we develop an online reinforcement learning (RL) algorithm for use in optimizing the delivery of mobile-based prompts to encourage oral hygiene behaviors. One of the main challenges in developing such an algorithm is ensuring that the algorithm considers the impact of the current action on the effectiveness of future actions (i.e., delayed effects), especially when the algorithm has been made simple in order to run stably and autonomously in a constrained, real-world setting (i.e., highly noisy, sparse data). We address this challenge by designing a quality reward which maximizes the desired health outcome (i.e., high-quality brushing) while minimizing user burden. We also highlight a procedure for optimizing the hyperparameters of the reward by building a simulation environment test bed and evaluating candidates using the test bed. The RL algorithm discussed in this paper will be deployed in Oralytics, an oral self-care app that provides behavioral strategies to boost patient engagement in oral hygiene practices.
In this paper, we develop an online reinforcement learning (RL) algorithm for use in optimizing the delivery of mobile-based prompts to encourage oral hygiene behaviors.
April 19, 2023
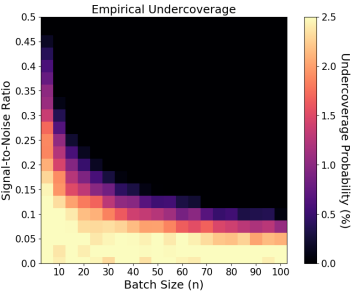
Online reinforcement learning and other adaptive sampling algorithms are increasingly used in digital intervention experiments to optimize treatment delivery for users over time. In this work, we focus on longitudinal user data collected by a large class of adaptive sampling algorithms that are designed to optimize treatment decisions online using accruing data from multiple users. Combining or “pooling” data across users allows adaptive sampling algorithms to potentially learn faster. However, by pooling, these algorithms induce dependence between the sampled user data trajectories; we show that this can cause standard variance estimators for i.i.d. data to underestimate the true variance of common estimators on this data type. We develop novel methods to perform a variety of statistical analyses on such adaptively sampled data via Z-estimation. Specifically, we introduce the adaptive sandwich variance estimator, a corrected sandwich estimator that leads to consistent variance estimates under adaptive sampling. Additionally, to prove our results we develop novel theoretical tools for empirical processes on non-i.i.d., adaptively sampled longitudinal data which may be of independent interest. This work is motivated by our efforts in designing experiments in which online reinforcement learning algorithms optimize treatment decisions, yet statistical inference is essential for conducting analyses after experiments conclude.
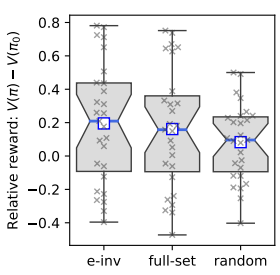
arXiv:2306.10983
June 27, 2023
effect-invariant mechanisms, policy generalization, machine learning
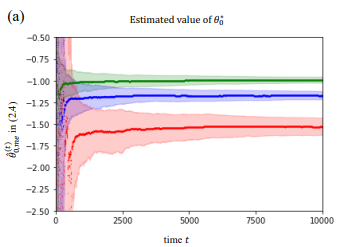
arXiv:2307.13916
October 31, 2023
contextual bandits, predicted context, online learning, machine learning
We consider the contextual bandit problem where at each time, the agent only has access to a noisy version of the context and the error variance (or an estimator of this variance). This setting is motivated by a wide range of applications where the true context for decision-making is unobserved, and only a prediction of the context by a potentially complex machine learning algorithm is available. When the context error is non-vanishing, classical bandit algorithms fail to achieve sublinear regret. We propose the first online algorithm in this setting with sublinear regret guarantees under mild conditions. The key idea is to extend the measurement error model in classical statistics to the online decision-making setting, which is nontrivial due to the policy being dependent on the noisy context observations. We further demonstrate the benefits of the proposed approach in simulation environments based on synthetic and real digital intervention datasets.
We propose the first online algorithm in this setting with sublinear regret guarantees under mild conditions.
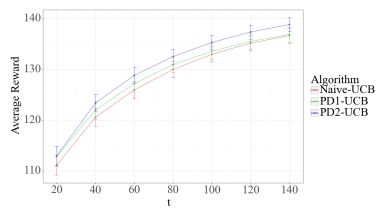
arXiv:2305.18511
May 29, 2023
machine learning, optimization and control, contextual bandits, information reveal
Contextual bandit algorithms are commonly used in digital health to recommend personalized treatments. However, to ensure the effectiveness of the treatments, patients are often requested to take actions that have no immediate benefit to them, which we refer to as pro-treatment actions. In practice, clinicians have a limited budget to encourage patients to take these actions and collect additional information. We introduce a novel optimization and learning algorithm to address this problem. This algorithm effectively combines the strengths of two algorithmic approaches in a seamless manner, including 1) an online primal-dual algorithm for deciding the optimal timing to reach out to patients, and 2) a contextual bandit learning algorithm to deliver personalized treatment to the patient. We prove that this algorithm admits a sub-linear regret bound. We illustrate the usefulness of this algorithm on both synthetic and real-world data.
We present an innovative optimization and learning algorithm to tackle the challenge clinicians face with constrained budgets, aiming to incentivize patients to take actions and gather additional information.
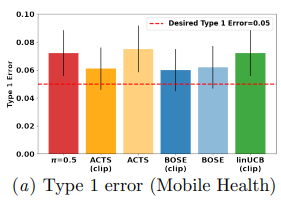
Proceedings of Machine Learning Research 149:1–50
contextual bandits, meta-algorithms, mobile health
August 2021
Contextual bandits often provide simple and effective personalization in decision making problems, making them popular tools to deliver personalized interventions in mobile health as well as other health applications. However, when bandits are deployed in the context of a scientific study — e.g. a clinical trial to test if a mobile health intervention is effective — the aim is not only to personalize for an individual, but also to determine, with sufficient statistical power, whether or not the system’s intervention is effective. It is essential to assess the effectiveness of the intervention before broader deployment for better resource allocation. The two objectives are often deployed under different model assumptions, making it hard to determine how achieving the personalization and statistical power affect each other. In this work, we develop general meta-algorithms to modify existing algorithms such that sufficient power is guaranteed while still improving each user’s well-being. We also demonstrate that our meta-algorithms are robust to various model mis-specifications possibly appearing in statistical studies, thus providing a valuable tool to study designers.
In this work, we develop general meta-algorithms to modify existing algorithms such that sufficient power is guaranteed while still improving each user’s well-being. We also demonstrate that our meta-algorithms are robust to various model mis-specifications possibly appearing in statistical studies, thus providing a valuable tool to study designers.
NAM Perspectives
mhealth interventions, mobile health
August 2021
Mobile Health (mHealth) technologies are now commonly used to deliver interventions in a self-service and personalized manner, reducing the demands on providers and lifting limitations on the locations in which care can be delivered.
Advances in Neural Information Processing Systems
bached bandits, ordinary least squares estimator
January 8, 2021

Statistical Science: a review journal of the Institute of Mathematical Statistics
causal inference, endogenous covariates, linear mixed model, micro-randomized trial
October 2020
Mobile health is a rapidly developing field in which behavioral treatments are delivered to individuals via wearables or smartphones to facilitate health-related behavior change. Micro-randomized trials (MRT) are an experimental design for developing mobile health interventions. In an MRT the treatments are randomized numerous times for each individual over course of the trial. Along with assessing treatment effects, behavioral scientists aim to understand between-person heterogeneity in the treatment effect. A natural approach is the familiar linear mixed model. However, directly applying linear mixed models is problematic because potential moderators of the treatment effect are frequently endogenous-that is, may depend on prior treatment. We discuss model interpretation and biases that arise in the absence of additional assumptions when endogenous covariates are included in a linear mixed model. In particular, when there are endogenous covariates, the coefficients no longer have the customary marginal interpretation. However, these coefficients still have a conditional-on-the-random-effect interpretation. We provide an additional assumption that, if true, allows scientists to use standard software to fit linear mixed model with endogenous covariates, and person-specific predictions of effects can be provided. As an illustration, we assess the effect of activity suggestion in the HeartSteps MRT and analyze the between-person treatment effect heterogeneity.
We discuss model interpretation and biases that arise in the absence of additional assumptions when endogenous covariates are included in a linear mixed model. In particular, when there are endogenous covariates, the coefficients no longer have the customary marginal interpretation.

Journal of the American Statistical Association
sequential decision making, policy evaluation, markov decision process, reinforcement learning
2021
In this paper, we provide an approach for conducting inference about the performance of one or more such policies using historical data collected under a possibly different policy.

Current Addiction Reports
addiction, just-in-time adaptive intervention, micro-randomized trial, mobile health
September 2020
Addiction is a serious and prevalent problem across the globe. An important challenge facing intervention science is how to support addiction treatment and recovery while mitigating the associated cost and stigma. A promising solution is the use of mobile health (mHealth) just-in-time adaptive interventions (JITAIs), in which intervention options are delivered in situ via a mobile device when individuals are most in need.
The present review describes the use of mHealth JITAIs to support addiction treatment and recovery, and provides guidance on when and how the micro-randomized trial (MRT) can be used to optimize a JITAI. We describe the design of five mHealth JITAIs in addiction and three MRT studies, and discuss challenges and future directions.
This review aims to provide guidance for constructing effective JITAIs to support addiction treatment and recovery.
arXiv: 2202.06891
February 14, 2022
sequential experiments, counterfactual inference, adaptive randomization, non-linear factor model, mixed effects model, nearest neighbors.
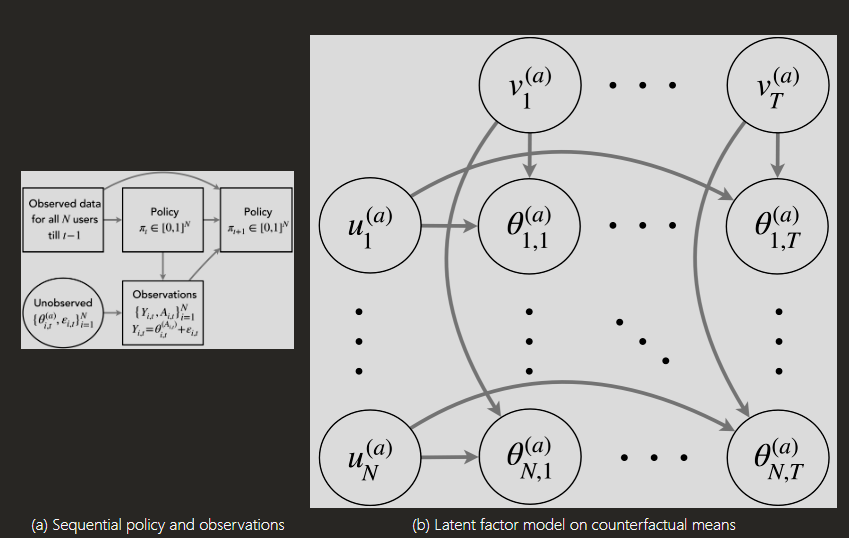
We consider after-study statistical inference for sequentially designed experiments wherein multiple units are assigned treatments for multiple time points using treatment policies that adapt over time. Our goal is to provide inference guarantees for the counterfactual mean at the smallest possible scale – mean outcome under different treatments for each unit and each time – with minimal assumptions on the adaptive treatment policy. Without any structural assumptions on the counterfactual means, this challenging task is infeasible due to more unknowns than observed data points. To make progress, we introduce a latent factor model over the counterfactual means that serves as a non-parametric generalization of the non-linear mixed effects model and the bilinear latent factor model considered in prior works. For estimation, we use a non-parametric method, namely a variant of nearest neighbors, and establish a non-asymptotic high probability error bound for the counterfactual mean for each unit and each time. Under regularity conditions, this bound leads to asymptotically valid confidence intervals for the counterfactual mean as the number of units and time points grows to together at suitable rates. We illustrate our theory via several simulations and a case study involving data from a mobile health clinical trial HeartSteps.
This publication presents a pioneering statistical inference method for sequential experiments where treatments are adaptively assigned to multiple units over time. It addresses the complex challenge of estimating unit-by-time level counterfactual outcomes by introducing a non-linear latent factor model and employing a nearest neighbors approach. The method provides non-asymptotic error bounds and asymptotically valid confidence intervals for counterfactual means, even with adaptive policies that pool data across units, making it highly applicable to real-world scenarios such as mobile health clinical trials like HeartSteps, online education, and personalized recommendations.

arXiv: 2410.14659
October 18, 2024
Reinforcement Learning (RL), Bagged Decision Times, Causal Directed Acyclic Graph (DAG), Non-Markovian, Non-stationary, Periodic Markov Decision Process (MDP), Dynamical Bayesian Sufficient Statistic (D-BaSS), Mobile Health (mHealth), HeartSteps, Online RL, Bellman Equations, Randomized Least-Squares Value Iteration (RLSVI), State Construction, Mediators.
We consider reinforcement learning (RL) for a class of problems with bagged decision times. A bag contains a finite sequence of consecutive decision times. The transition dynamics are non-Markovian and non-stationary within a bag. All actions within a bag jointly impact a single reward, observed at the end of the bag. For example, in mobile health, multiple activity suggestions in a day collectively affect a user’s daily commitment to being active. Our goal is to develop an online RL algorithm to maximize the discounted sum of the bag-specific rewards. To handle non-Markovian transitions within a bag, we utilize an expert-provided causal directed acyclic graph (DAG). Based on the DAG, we construct states as a dynamical Bayesian sufficient statistic of the observed history, which results in Markov state transitions within and across bags. We then formulate this problem as a periodic Markov decision process (MDP) that allows non-stationarity within a period. An online RL algorithm based on Bellman equations for stationary MDPs is generalized to handle periodic MDPs. We show that our constructed state achieves the maximal optimal value function among all state constructions for a periodic MDP. Finally, we evaluate the proposed method on testbed variants built from real data in a mobile health clinical trial.
This publication introduces a novel Reinforcement Learning (RL) framework designed for scenarios with “bagged decision times,” where a sequence of actions within a finite period (a “bag”) jointly influences a single reward observed at the end of that period. Unlike traditional RL that often assumes Markovian and stationary transitions, this work addresses non-Markovian and non-stationary dynamics within a bag. The core innovation lies in leveraging an expert-provided causal Directed Acyclic Graph (DAG) to construct states (specifically, a dynamical Bayesian sufficient statistic) that ensure Markovian transitions both within and across bags. This allows the problem to be formulated as a periodic Markov Decision Process (MDP), generalizing existing RL algorithms based on Bellman equations. The proposed online RL algorithm, Bagged RLSVI, is shown to achieve maximal optimal value functions and is evaluated effectively on testbed variants built from real mobile health (mHealth) data (HeartSteps clinical trial), demonstrating its robustness even with misspecified causal assumptions. The research highlights the significant role of mediators in improving the optimal value function.

Nature
NPJ Digital Medicine
September 14, 2023
mHealth, Cardiac rehabilitation (CR), Randomized clinical trial, Just-in-time adaptive intervention (JITAI), Smartwatch, Smartphone, Physical activity, 6-minute walk test, Cardiovascular disease, Text messages, Mobile application.
Mobile health (mHealth) interventions may enhance positive health behaviors, but randomized trials evaluating their efficacy are uncommon. Our goal was to determine if a mHealth intervention augmented and extended benefits of center-based cardiac rehabilitation (CR) for physical activity levels at 6-months. We delivered a randomized clinical trial to low and moderate risk patients with a compatible smartphone enrolled in CR at two health systems. All participants received a compatible smartwatch and usual CR care. Intervention participants received a mHealth intervention that included a just-in-time-adaptive intervention (JITAI) as text messages. The primary outcome was change in remote 6-minute walk distance at 6-months stratified by device type. Here we report the results for 220 participants enrolled in the study (mean [SD]: age 59.6 [10.6] years; 67 [30.5%] women). For our primary outcome at 6 months, there is no significant difference in the change in 6 min walk distance across smartwatch types (Intervention versus control: +31.1 meters Apple Watch, −7.4 meters Fitbit; p = 0.28). Secondary outcomes show no difference in mean step counts between the first and final weeks of the study, but a change in 6 min walk distance at 3 months for Fitbit users. Amongst patients enrolled in center-based CR, a mHealth intervention did not improve 6-month outcomes but suggested differences at 3 months in some users.
This randomized clinical trial, named the VALENTINE Study, investigated whether a mobile health (mHealth) intervention—consisting of a smartphone application and contextually tailored text messages delivered via smartwatches—could augment and extend the benefits of center-based cardiac rehabilitation (CR) by improving physical activity levels over 6 months. The study enrolled 220 low and moderate risk CR patients who were provided with either an Apple Watch or Fitbit. The primary outcome, change in remote 6-minute walk distance at 6-months, showed no significant difference between the intervention and control groups. While there were suggestive differences at 3 months for Fitbit users regarding 6-minute walk distance, the intervention did not achieve its goal of sustained long-term impact on physical activity.
Biometrika
binary outcome, causal excursion effect, causal inference, longitudinal data, micro-randomized trials, mobile health, relative risk, semiparametric efficiency theory
September 2021
We develop an estimator that can be used as the basis of a primary aim analysis under more plausible assumptions. Simulation studies are conducted to compare the estimators. We illustrate the developed methods using data from the MRT, BariFit. In BariFit, the goal is to support weight maintenance for individuals who received bariatric surgery.

Transactions on Machine Learning Research
November 2023
Online model selection, compositional kernels, Gaussian Process regression, multi-task learning, mobile health (mHealth), Kernel Evolution Model (KEM), personalized learning, bias-variance trade-off, sparsity, stability, adaptive complexity, Dirichlet Process, Chinese Restaurant Process, kernel evolution.
Motivated by the need for efficient, personalized learning in mobile health, we investigate the problem of online compositional kernel selection for multi-task Gaussian Process regression. Existing composition selection methods do not satisfy our strict criteria in health; selection must occur quickly, and the selected kernels must maintain the appropriate level of complexity, sparsity, and stability as data arrives online. We introduce the Kernel Evolution Model (KEM), a generative process on how to evolve kernel compositions in a way that manages the bias-variance trade-off as we observe more data about a user. Using pilot data, we learn a set of kernel evolutions that can be used to quickly select kernels for new test users. KEM reliably selects high-performing kernels for a range of synthetic and real data sets, including two health data sets.
This publication introduces the Kernel Evolution Model (KEM), an innovative approach for online compositional kernel selection in multi-task Gaussian Process regression, specifically designed for mobile health (mHealth) applications. KEM addresses the critical need for efficient, personalized learning by training on pilot data to learn how kernel compositions should evolve over time. This allows KEM to quickly select high-performing kernels for new users that are sparse, stable, and possess adaptive complexity, effectively managing the bias-variance trade-off, especially in low-data scenarios.
arXiv: 2409.02069
September 3, 2024
Reinforcement Learning, mHealth, Clinical Trials, Oral Health, Oral Self-Care Behaviors, Thompson Sampling, Contextual Bandits, Deployment, Replicability, Adaptive Interventions
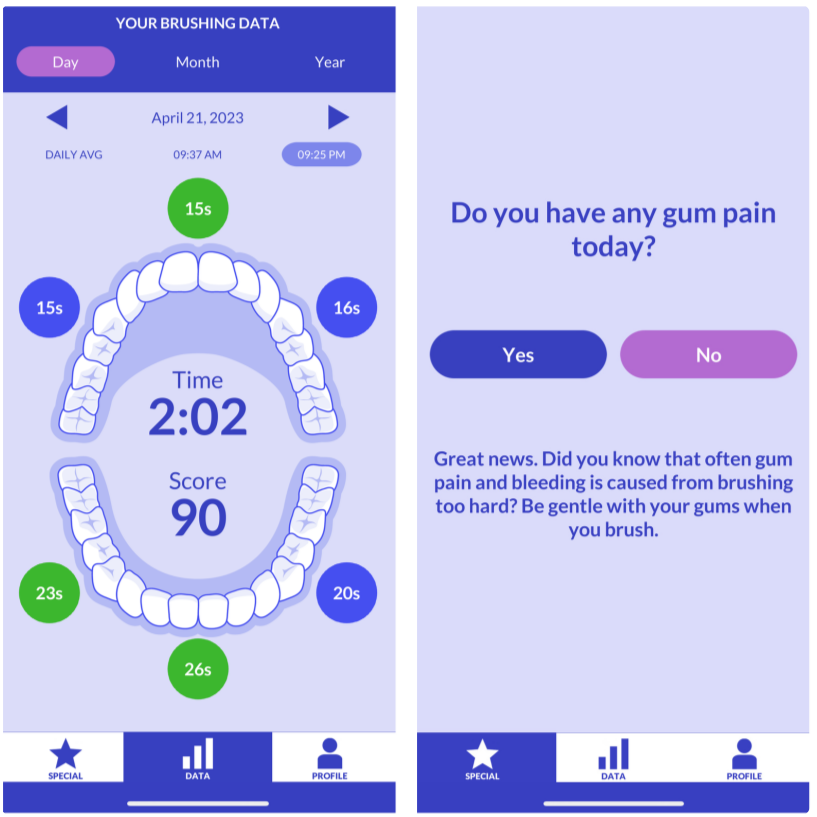
Dental disease is a prevalent chronic condition associated with substantial financial burden, personal suffering, and increased risk of systemic diseases. Despite widespread recommendations for twice-daily tooth brushing, adherence to recommended oral self-care behaviors remains sub-optimal due to factors such as forgetfulness and disengagement. To address this, we developed Oralytics, a mHealth intervention system designed to complement clinician-delivered preventative care for marginalized individuals at risk for dental disease. Oralytics incorporates an online reinforcement learning algorithm to determine optimal times to deliver intervention prompts that encourage oral self-care behaviors. We have deployed Oralytics in a registered clinical trial. The deployment required careful design to manage challenges specific to the clinical trials setting in the U.S. In this paper, we (1) highlight key design decisions of the RL algorithm that address these challenges and (2) conduct a re-sampling analysis to evaluate algorithm design decisions. A second phase (randomized control trial) of Oralytics is planned to start in spring 2025.
This paper introduces Oralytics, an mHealth intervention system that leverages an online reinforcement learning (RL) algorithm to optimize the delivery of engagement prompts aimed at improving oral self-care behaviors (OSCB) in individuals at risk for dental disease. The authors detail the key design decisions for deploying this RL algorithm within a registered clinical trial setting, addressing challenges such as ensuring autonomy and replicability through methods like pre-scheduling actions and implementing fallback procedures, and dealing with limited per-individual data by using a full-pooling approach. Through re-sampling analysis, the study provides evidence that the algorithm successfully learned to identify states where sending prompts was effective or ineffective.
Alexandra M Psihogios, Ayah El-Khatib, Kevin Matos, Mashfiqui Rabbi, Jenna Rossoff, Shira Dinner, Kristy Zeng, Raymundo Picos, Annisa Ahmed, Esha M Patel, Linda Fleisher, Stephen P Hunger, Ahna Pai, Jean-Philippe Laurenceau, Christine Rini , Lamia P Barakat, Lisa A Schwartz, Susan A. Murphy, Betina Yanez
May 9, 2025
6‐mercaptopurine; acute lymphoblastic leukemia; adherence; adolescent; mobile health; young adult.
Background: Acute lymphoblastic leukemia/lymphoma therapy includes a maintenance phase involving daily administration of an oral chemotherapy called 6-mercaptopurine (6-MP). Adolescents and young adults (AYAs) exhibit lower 6-MP adherence than younger patients, which increases their relapse risk. However, effective oral chemotherapy adherence interventions for this AYA population are lacking.
Objective: This study describes the human-centered design process of co-creating ADAPTS, an app-based just-in-time adaptive intervention for 6-MP adherence in AYAs.
Methods: Across three design waves with input from AYAs (n = 19) and their caregivers (n = 14), we conducted interviews to co-develop and refine ADAPTS. Qualitative data were coded using conventional content analysis to identify themes that informed app design.
Results: Four design priorities for an oral chemotherapy adherence digital intervention were identified: (i) personalize messages to the contextual factors that fluctuate and impact adherence, such as symptoms and mood; (ii) enhance the persuasiveness of adherence messages by framing them positively (e.g., a focus on maintaining remission rather than preventing a relapse), and including the perspectives of peers in popular social media formats; (iii) include customizable app features and the ability to track personal adherence progress; and (iv) facilitate dyadic adherence communication between AYAs and their caregivers, who are often involved.
Conclusions: By developing ADAPTS with AYAs and their caregivers, this digital health intervention offers a novel and patient-centric approach to enhancing adherence. The resulting design priorities and human-centered design methods employed have generalizable potential for addressing other AYA cancer health behaviors.
The Annals of Statistics
December 21, 2022
average reward, doubly robust estimator, Markov Decision Process, policy optimization
We consider the batch (off-line) policy learning problem in the infinite horizon Markov decision process. Motivated by mobile health applications, we focus on learning a policy that maximizes the long-term average reward. We propose a doubly robust estimator for the average reward and show that it achieves semiparametric efficiency. Further, we develop an optimization algorithm to compute the optimal policy in a parameterized stochastic policy class. The performance of the estimated policy is measured by the difference between the optimal average reward in the policy class and the average reward of the estimated policy and we establish a finite-sample regret guarantee. The performance of the method is illustrated by simulation studies and an analysis of a mobile health study promoting physical activity.
We consider batch policy learning in an infinite horizon Markov Decision Process, focusing on optimizing a policy for long-term average reward in the context of mobile health applications.

IEEE International Conference on Digital Health (ICDH)
July 10, 2022
learning systems, optimized production technology, behavioral sciences, electronic healthcare, decision trees
To promote healthy behaviors, many mobile health applications provide message-based interventions, such as tips, motivational messages, or suggestions for healthy activities. Ideally, the intervention policies should be carefully designed so that users obtain the benefits without being overwhelmed by overly frequent messages. As part of the HeartSteps physical-activity intervention, users receive messages intended to disrupt sedentary behavior. HeartSteps uses an algorithm to uniformly spread out the daily message budget over time, but does not attempt to maximize treatment effects. This limitation motivates constructing a policy to optimize the message delivery decisions for more effective treatments. Moreover, the learned policy needs to be interpretable to enable behavioral scientists to examine it and to inform future theorizing. We address this problem by learning an effective and interpretable policy that reduces sedentary behavior. We propose Optimal Policy Trees + (OPT+), an innovative batch off-policy learning method, that combines a personalized threshold learning and an extension of Optimal Policy Trees under a budget-constrained setting. We implement and test the method using data collected in HeartSteps V2N3. Computational results demonstrate a significant reduction in sedentary behavior with a lower delivery budget. OPT + produces a highly interpretable and stable output decision tree thus enabling theoretical insights to guide future research.
Online RL faces challenges like real-time stability and handling complex, unpredictable environments; to address these issues, the PCS framework originally used in supervised learning is extended to guide the design of RL algorithms for such settings, including guidelines for creating simulation environments, as exemplified in the development of an RL algorithm for the mobile health study Oralytics aimed at enhancing tooth-brushing behaviors through personalized intervention messages.

NIH National Library of Medicine: National Center for Biotechnology Information – ClinicalTrials.gov, Identifier: NCT05624489
Submission Under Review
engagement strategies, dental disease, health behavior change, oral self-care behaviors
The study will involve a 10-week Micro-Randomized Trial (MRT) to inform the delivery of prompts (via mobile app push notifications) designed to facilitate adherence to an ideal tooth brushing protocol (2x2x4; 2 sessions daily, 2 minutes per session, all 4 quadrants).
arXiv:2304.05365v6
August 7, 2023
reinforcement learning, personalization, resampling, exploratory data analysis, mobile health
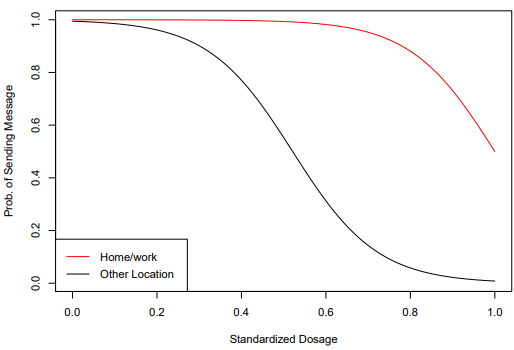
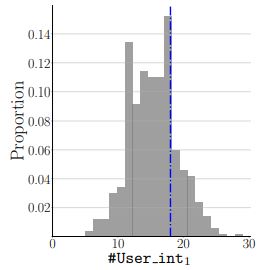
There is a growing interest in using reinforcement learning (RL) to personalize sequences of treatments in digital health to support users in adopting healthier behaviors. Such sequential decision-making problems involve decisions about when to treat and how to treat based on the user’s context (e.g., prior activity level, location, etc.). Online RL is a promising data-driven approach for this problem as it learns based on each user’s historical responses and uses that knowledge to personalize these decisions. However, to decide whether the RL algorithm should be included in an “optimized” intervention for real-world deployment, we must assess the data evidence indicating that the RL algorithm is actually personalizing the treatments to its users. Due to the stochasticity in the RL algorithm, one may get a false impression that it is learning in certain states and using this learning to provide specific treatments. We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity. We illustrate our methodology with a case study by analyzing the data from a physical activity clinical trial called HeartSteps, which included the use of an online RL algorithm. We demonstrate how our approach enhances data-driven truth-in-advertising of algorithm personalization both across all users as well as within specific users in the study.
We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity.

JMIR Formative Research
December 11, 2023
engagement, oral health, mobile health intervention, racial and ethnic minority group, message development
Background: The prevention of oral health diseases is a key public health issue and a major challenge for racial and ethnic minority groups, who often face barriers in accessing dental care. Daily toothbrushing is an important self-care behavior necessary for sustaining good oral health, yet engagement in regular brushing remains a challenge. Identifying strategies to promote engagement in regular oral self-care behaviors among populations at risk of poor oral health is critical.
Objective: The formative research described here focused on creating messages for a digital oral self-care intervention targeting a racially and ethnically diverse population. Theoretically grounded strategies (reciprocity, reciprocity-by-proxy, and curiosity) were used to promote engagement in 3 aspects: oral self-care behaviors, an oral care smartphone app, and digital messages. A web-based participatory co-design approach was used to develop messages that are resource efficient, appealing, and novel; this approach involved dental experts, individuals from the general population, and individuals from the target population—dental patients from predominantly low-income racial and ethnic minority groups. Given that many individuals from racially and ethnically diverse populations face anonymity and confidentiality concerns when participating in research, we used an approach to message development that aimed to mitigate these concerns.
Methods: Messages were initially developed with feedback from dental experts and Amazon Mechanical Turk workers. Dental patients were then recruited for 2 facilitator-mediated group webinar sessions held over Zoom (Zoom Video Communications; session 1: n=13; session 2: n=7), in which they provided both quantitative ratings and qualitative feedback on the messages. Participants interacted with the facilitator through Zoom polls and a chat window that was anonymous to other participants. Participants did not directly interact with each other, and the facilitator mediated sessions by verbally asking for message feedback and sharing key suggestions with the group for additional feedback. This approach plausibly enhanced participant anonymity and confidentiality during the sessions.
Results: Participants rated messages highly in terms of liking (overall rating: mean 2.63, SD 0.58; reciprocity: mean 2.65, SD 0.52; reciprocity-by-proxy: mean 2.58, SD 0.53; curiosity involving interactive oral health questions and answers: mean 2.45, SD 0.69; curiosity involving tailored brushing feedback: mean 2.77, SD 0.48) on a scale ranging from 1 (do not like it) to 3 (like it). Qualitative feedback indicated that the participants preferred messages that were straightforward, enthusiastic, conversational, relatable, and authentic.
Conclusions: This formative research has the potential to guide the design of messages for future digital health behavioral interventions targeting individuals from diverse racial and ethnic populations. Insights emphasize the importance of identifying key stimuli and tasks that require engagement, gathering multiple perspectives during message development, and using new approaches for collecting both quantitative and qualitative data while mitigating anonymity and confidentiality concerns.
The formative research described here focused on creating messages for a digital oral self-care intervention targeting a racially and ethnically diverse population. Theoretically grounded strategies (reciprocity, reciprocity-by-proxy, and curiosity) were used to promote engagement in 3 aspects: oral self-care behaviors, an oral care smartphone app, and digital messages.

To appear in Volume 20 of the Annual Review of Clinical Psychology, 2023
2023
engagement, oral health, mobile health intervention, racial and ethnic minority group, message development
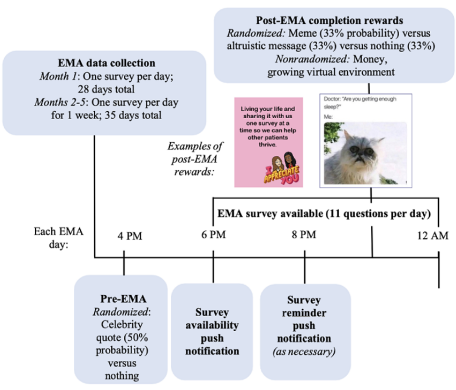
JMIR Research Protocols
ecological momentary assessment, adolescents, young adults, oncology, cancer, self-management, mobile health (mHealth)
October 22, 2021
Background: Adolescents and young adults (AYAs) with cancer demonstrate suboptimal oral chemotherapy adherence, increasing their risk of cancer relapse. It is unclear how everyday time-varying contextual factors (eg, mood) affect their adherence, stalling the development of personalized mobile health (mHealth) interventions. Poor engagement is also a challenge across mHealth trials; an effective adherence intervention must be engaging to promote uptake.
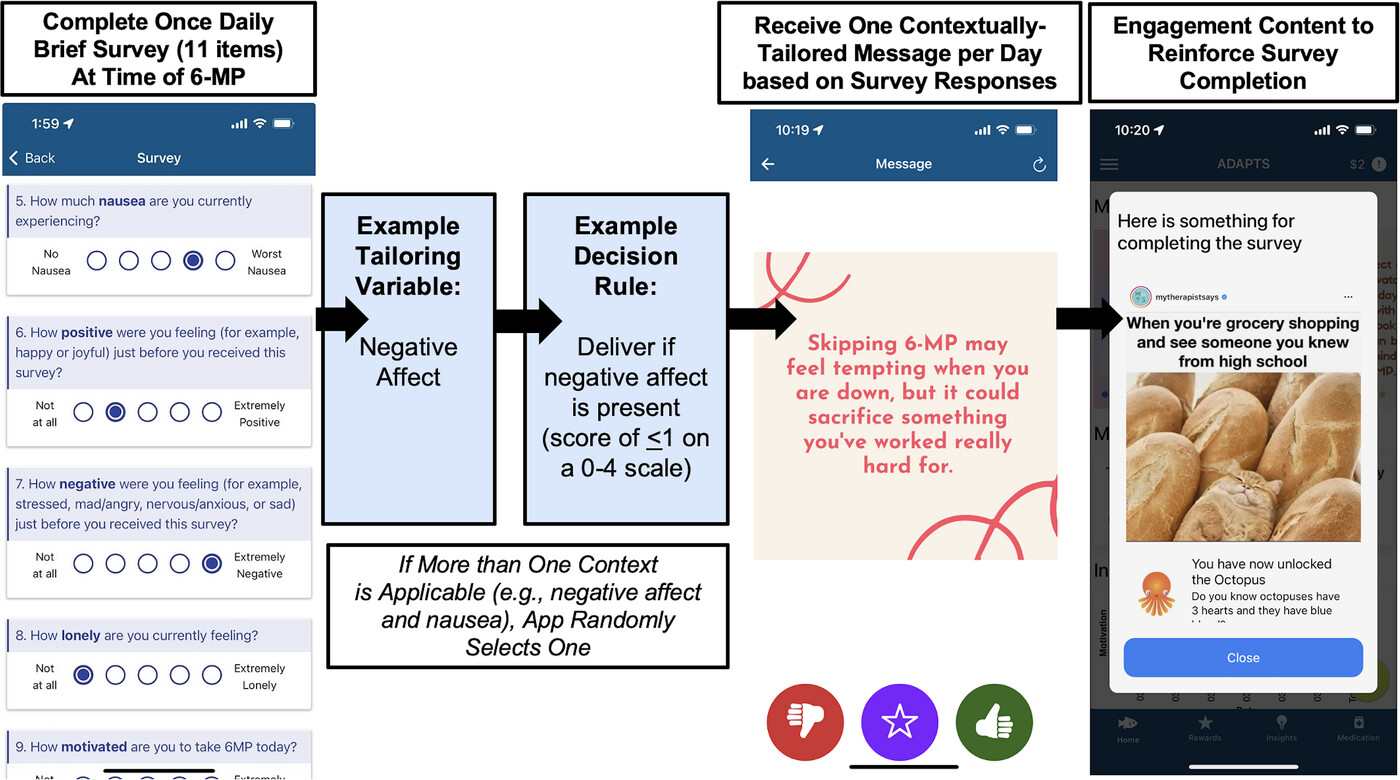
Objective: This protocol aims to determine the temporal associations between daily contextual factors and 6-mercaptopurine (6-MP) adherence and explore the proximal impact of various engagement strategies on ecological momentary assessment survey completion.
Methods: At the Children s Hospital of Philadelphia, AYAs with acute lymphoblastic leukemia or lymphoma who are prescribed prolonged maintenance chemotherapy that includes daily oral 6-MP are eligible, along with their matched caregivers. Participants will use an ecological momentary assessment app called ADAPTS (Adherence Assessments and Personalized Timely Support) a version of an open-source app that was modified for AYAs with cancer through a user-centered process and complete surveys in bursts over 6 months. Theory-informed engagement strategies will be microrandomized to estimate the causal effects on proximal survey completion.
Results: With funding from the National Cancer Institute and institutional review board approval, of the proposed 30 AYA-caregiver dyads, 60% (18/30) have been enrolled; of the 18 enrolled, 15 (83%) have completed the study so far.
Conclusions: This protocol represents an important first step toward prescreening tailoring variables and engagement components for a just-in-Time adaptive intervention designed to promote both 6-MP adherence and mHealth engagement.
This protocol represents an important first step toward prescreening tailoring variables and engagement components for a just-in-Time adaptive intervention designed to promote both 6-MP adherence and mHealth engagement.
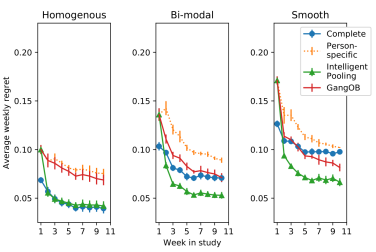
Machine Learning, Volume 110, Pages 2685–2727
Thompson-Sampling, mobile health, reinforcement learning
September 2021
In mobile health (mHealth) smart devices deliver behavioral treatments repeatedly over time to a user with the goal of helping the user adopt and maintain healthy behaviors. Reinforcement learning appears ideal for learning how to optimally make these sequential treatment decisions. However, significant challenges must be overcome before reinforcement learning can be effectively deployed in a mobile healthcare setting. In this work we are concerned with the following challenges: 1) individuals who are in the same context can exhibit differential response to treatments 2) only a limited amount of data is available for learning on any one individual, and 3) non-stationary responses to treatment. To address these challenges we generalize Thompson-Sampling bandit algorithms to develop IntelligentPooling. IntelligentPooling learns personalized treatment policies thus addressing challenge one. To address the second challenge, IntelligentPooling updates each user’s degree of personalization while making use of available data on other users to speed up learning. Lastly, IntelligentPooling allows responsivity to vary as a function of a user’s time since beginning treatment, thus addressing challenge three. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art. We demonstrate the promise of this approach and its ability to learn from even a small group of users in a live clinical trial.
To address the significant challenges that must be overcome before reinforcement learning can be deployed in a mobile healthcare setting, we develop IntelligentPooling by generalizing Thompson-Sampling bandit algorithms.
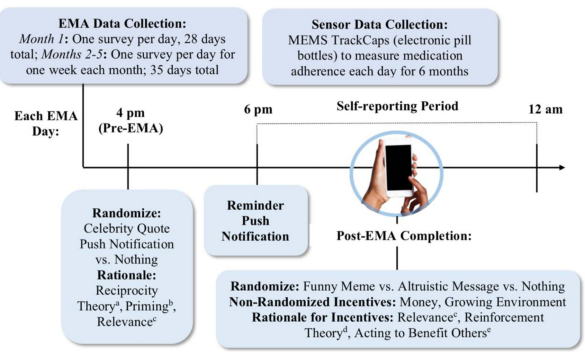
Current Opinion in Systems Biology
adolescent, young adult, chemotherapy adherance, micro-randomized trial
June 2020
Long-term engagement with mobile health (mHealth) apps can provide critical data for improving empirical models for real-time health behaviors. To learn how to improve and maintain mHealth engagement, micro-randomized trials (MRTs) can be used to optimize different engagement strategies. In MRTs, participants are sequentially randomized, often hundreds or thousands of times, to different engagement strategies or treatments. The data gathered are then used to decide which treatment is optimal in which context. In this paper, we discuss an example MRT for youth with cancer, where we randomize different engagement strategies to improve self-reports on factors related to medication adherence. MRTs, moreover, can go beyond improving engagement, and we reference other MRTs to address substance abuse, sedentary behavior, and so on.
In this paper, we discuss an example MRT for youth with cancer, where we randomize different engagement strategies to improve self-reports on factors related to medication adherence.
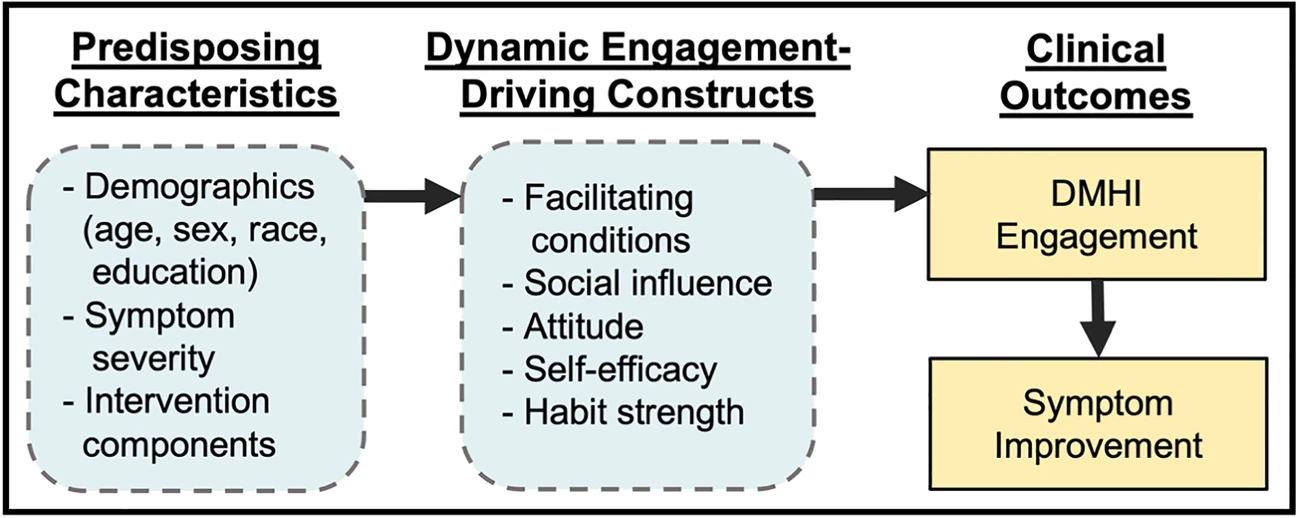
Current Treatment Options in Psychiatry
September 2023
Engagement, Digital
interventions, Adherence, Adoption, Reporting guidelines, Model of engagement, Mental health,Cyberpsychology, Health Psychology, Internet
psychology, Behavioral Science and Psychology, Public Engagement with Science.
Digital Mental Health Interventions (DMHIs) offer a promising solution to widespread mental illness but face a major problem: patients often don’t engage with them enough to see clinical benefits. This publication reviews how engagement is influenced by patient, intervention, and system-level factors, such as demographics, human support, gamification, financial incentives, persuasive technology, and healthcare system integration. To address this “engagement problem,” which is fundamentally an implementation challenge, the authors recommend standardizing engagement reporting, using alternative clinical trial designs, and developing a robust theory of DMHI engagement through rigorous research.
arXiv: 2409.02069
September 3, 2024
Reinforcement Learning, mHealth, Clinical Trials, Oral Health, Oral Self-Care Behaviors, Thompson Sampling, Contextual Bandits, Deployment, Replicability, Adaptive Interventions
Dental disease is a prevalent chronic condition associated with substantial financial burden, personal suffering, and increased risk of systemic diseases. Despite widespread recommendations for twice-daily tooth brushing, adherence to recommended oral self-care behaviors remains sub-optimal due to factors such as forgetfulness and disengagement. To address this, we developed Oralytics, a mHealth intervention system designed to complement clinician-delivered preventative care for marginalized individuals at risk for dental disease. Oralytics incorporates an online reinforcement learning algorithm to determine optimal times to deliver intervention prompts that encourage oral self-care behaviors. We have deployed Oralytics in a registered clinical trial. The deployment required careful design to manage challenges specific to the clinical trials setting in the U.S. In this paper, we (1) highlight key design decisions of the RL algorithm that address these challenges and (2) conduct a re-sampling analysis to evaluate algorithm design decisions. A second phase (randomized control trial) of Oralytics is planned to start in spring 2025.
This paper introduces Oralytics, an mHealth intervention system that leverages an online reinforcement learning (RL) algorithm to optimize the delivery of engagement prompts aimed at improving oral self-care behaviors (OSCB) in individuals at risk for dental disease. The authors detail the key design decisions for deploying this RL algorithm within a registered clinical trial setting, addressing challenges such as ensuring autonomy and replicability through methods like pre-scheduling actions and implementing fallback procedures, and dealing with limited per-individual data by using a full-pooling approach. Through re-sampling analysis, the study provides evidence that the algorithm successfully learned to identify states where sending prompts was effective or ineffective.
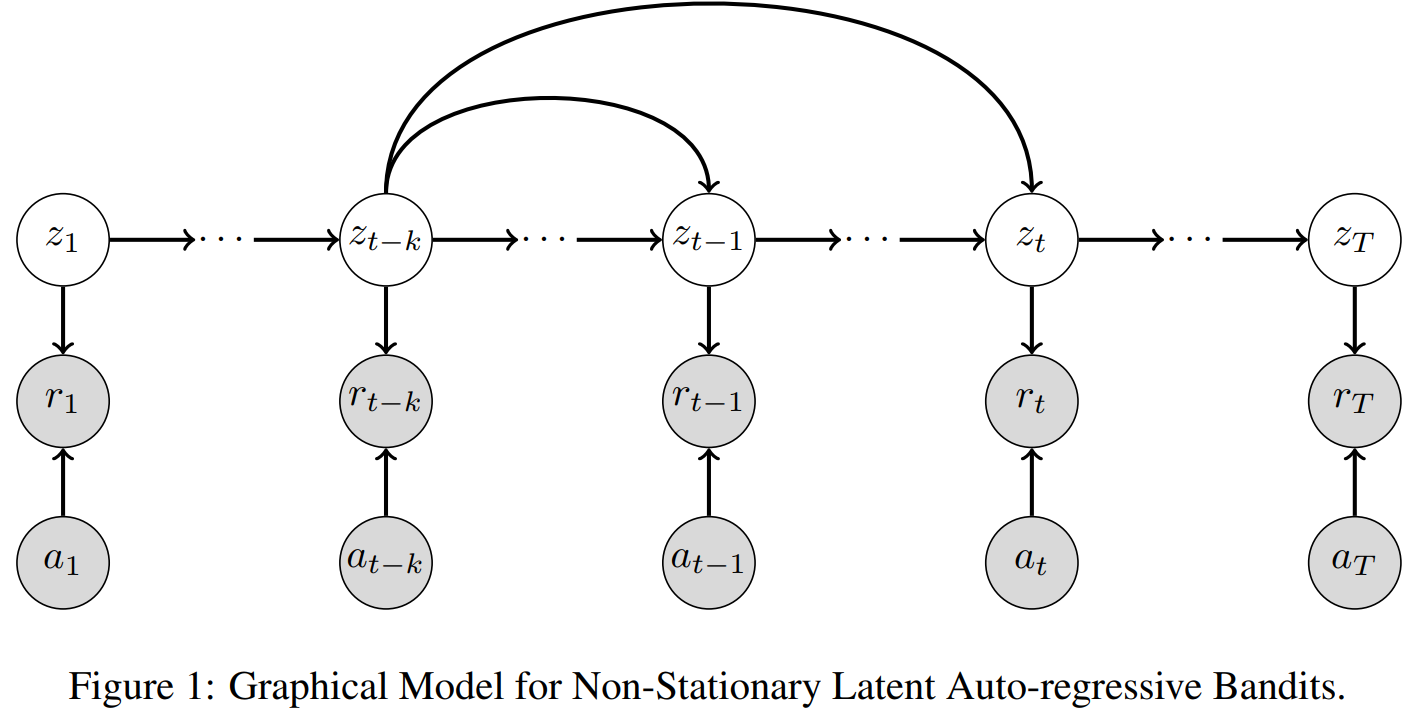
arXiv: 2402.03110
February 3, 2024
contextual bandits, bandit algorithms, non-stationarity
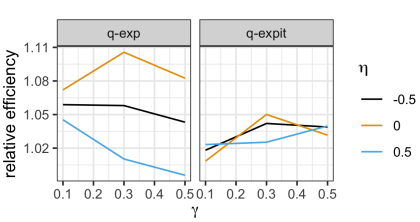
For the non-stationary multi-armed bandit (MAB) problem, many existing methods allow a general mechanism for the non-stationarity, but rely on a budget for the non-stationarity that is sub-linear to the total number of time steps . In many real-world settings, however, the mechanism for the non-stationarity can be modeled, but there is no budget for the non-stationarity. We instead consider the non-stationary bandit problem where the reward means change due to a latent, auto-regressive (AR) state. We develop Latent AR LinUCB (LARL), an online linear contextual bandit algorithm that does not rely on the non-stationary budget, but instead forms good predictions of reward means by implicitly predicting the latent state. The key idea is to reduce the problem to a linear dynamical system which can be solved as a linear contextual bandit. In fact, LARL approximates a steady-state Kalman filter and efficiently learns system parameters online. We provide an interpretable regret bound for LARL with respect to the level of non-stationarity in the environment. LARL achieves sub-linear regret in this setting if the noise variance of the latent state process is sufficiently small with respect to . Empirically, LARL outperforms various baseline methods in this non-stationary bandit problem.
This paper introduces Latent AR LinUCB (LARL), an efficient online algorithm designed for non-stationary multi-armed bandit (MAB) problems. Unlike many existing methods that rely on a budget for non-stationarity, LARL addresses settings where reward means change due to an unbudgeted, latent, auto-regressive (AR) state. It effectively forms good predictions of reward means by implicitly predicting the latent state. This is achieved by reducing the problem to a linear dynamical system solvable as a linear contextual bandit, which approximates a steady-state Kalman filter and learns parameters online. LARL achieves sub-linear regret under specific conditions related to the latent state noise variance and outperforms various stationary and non-stationary baseline methods in simulations.
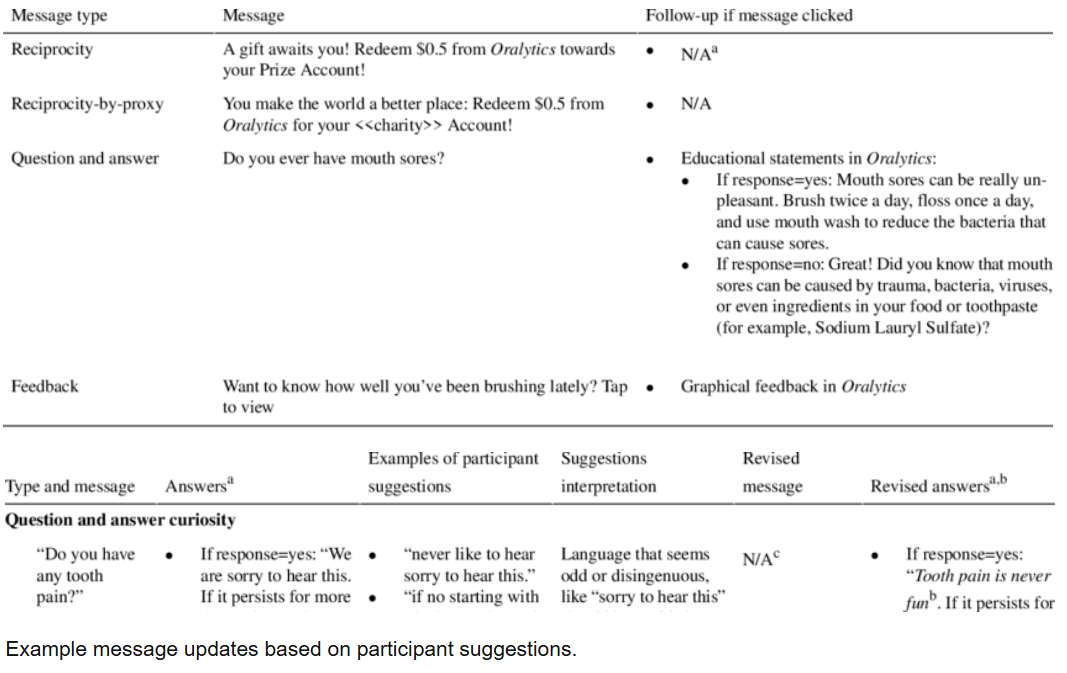
JMIR Formative Research
December 11, 2023
contextual bandits, bandit algorithms, non-stationarity
This publication describes research focused on creating effective digital messages to promote oral self-care, particularly daily toothbrushing, among diverse racial and ethnic minority groups. The goal was to develop engaging and appealing content for a smartphone application that would encourage better oral health habits. The development process involved collaborative design with dental experts and members of the target population, using web-based sessions to gather feedback while prioritizing participant anonymity and confidentiality. The findings indicate a preference for clear, enthusiastic, and relatable messages, suggesting valuable insights for future digital health interventions aimed at improving public health behaviors in vulnerable communities.
This publication details formative research aimed at developing and refining digital oral health messages for a smartphone app called Oralytics, targeting diverse racial and ethnic minority populations to promote daily toothbrushing. The study utilized theoretically grounded strategies such as reciprocity, reciprocity-by-proxy, and curiosity to enhance engagement with oral self-care behaviors, the app, and the messages themselves. Messages were developed using a web-based participatory co-design approach involving dental experts, Amazon Mechanical Turk workers, and dental patients. This approach notably focused on mitigating anonymity and confidentiality concerns during participant feedback sessions, which were conducted via facilitator-mediated Zoom webinars. Participants rated the messages highly, with qualitative feedback emphasizing a preference for messages that were straightforward, enthusiastic, conversational, relatable, and authentic. The research provides insights into designing engaging digital health interventions for underserved populations, stressing the importance of identifying key stimuli, gathering multiple perspectives, and employing innovative, secure data collection methods.
arXiv:2304.05365v6
August 7, 2023
reinforcement learning, personalization, resampling, exploratory data analysis, mobile health
There is a growing interest in using reinforcement learning (RL) to personalize sequences of treatments in digital health to support users in adopting healthier behaviors. Such sequential decision-making problems involve decisions about when to treat and how to treat based on the user’s context (e.g., prior activity level, location, etc.). Online RL is a promising data-driven approach for this problem as it learns based on each user’s historical responses and uses that knowledge to personalize these decisions. However, to decide whether the RL algorithm should be included in an “optimized” intervention for real-world deployment, we must assess the data evidence indicating that the RL algorithm is actually personalizing the treatments to its users. Due to the stochasticity in the RL algorithm, one may get a false impression that it is learning in certain states and using this learning to provide specific treatments. We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity. We illustrate our methodology with a case study by analyzing the data from a physical activity clinical trial called HeartSteps, which included the use of an online RL algorithm. We demonstrate how our approach enhances data-driven truth-in-advertising of algorithm personalization both across all users as well as within specific users in the study.
We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity.

December 14, 2024
Reinforcement Learning, Thompson Sampling, Bayesian Optimization, Adaptive Interventions, Episode-Limited Learning, Batch Learning.

Proceedings of the 23rd ACM Conference on Embedded Networked Sensor Systems
December 14, 2024
Reinforcement Learning, Just-In-Time Adaptive Interventions, Physical Activity, Simulation Environment, Mobile Health, Adaptive Interventions.
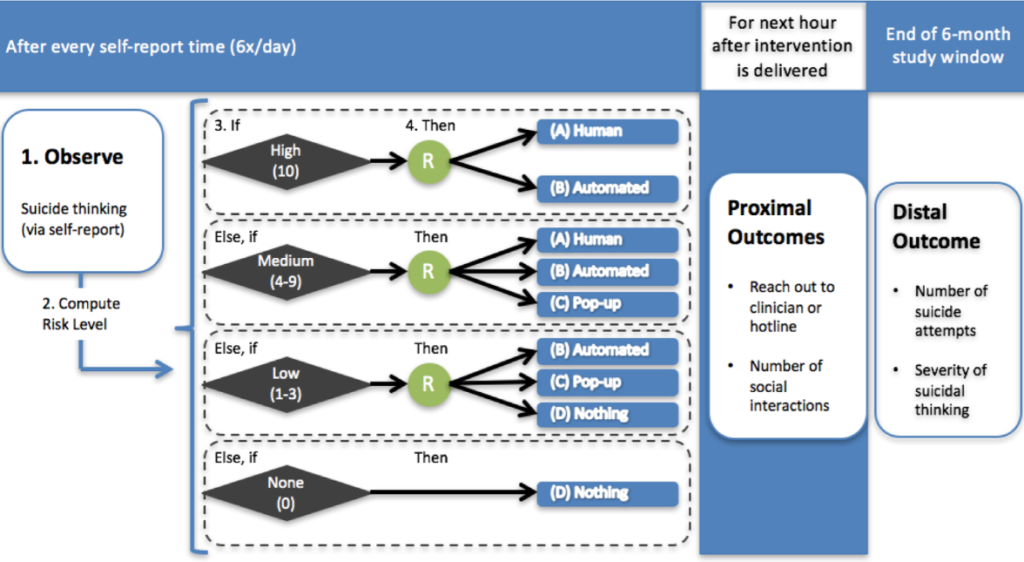
Psychiatry: Interpersonal and Biological Processes
July 18, 2022
suicide, self-injury, just-in-time adaptive interventions
The suicide rate (currently 14 per 100,000) has barely changed in the United States over the past 100 years. There is a need for new ways of preventing suicide. Further, research has revealed that suicidal thoughts and behaviors and the factors that drive them are dynamic, heterogeneous, and interactive. Most existing interventions for suicidal thoughts and behaviors are infrequent, not accessible when most needed, and not systematically tailored to the person using their own data (e.g., from their own smartphone). Advances in technology offer an opportunity to develop new interventions that may better match the dynamic, heterogeneous, and interactive nature of suicidal thoughts and behaviors. Just-In-Time Adaptive Interventions (JITAIs), which use smartphones and wearables, are designed to provide the right type of support at the right time by adapting to changes in internal states and external contexts, offering a promising pathway toward more effective suicide prevention. In this review, we highlight the potential of JITAIs for suicide prevention, challenges ahead (e.g., measurement, ethics), and possible solutions to these challenges.
In this review, we highlight the potential of JITAIs for suicide prevention, challenges ahead (e.g., measurement, ethics), and possible solutions to these challenges.
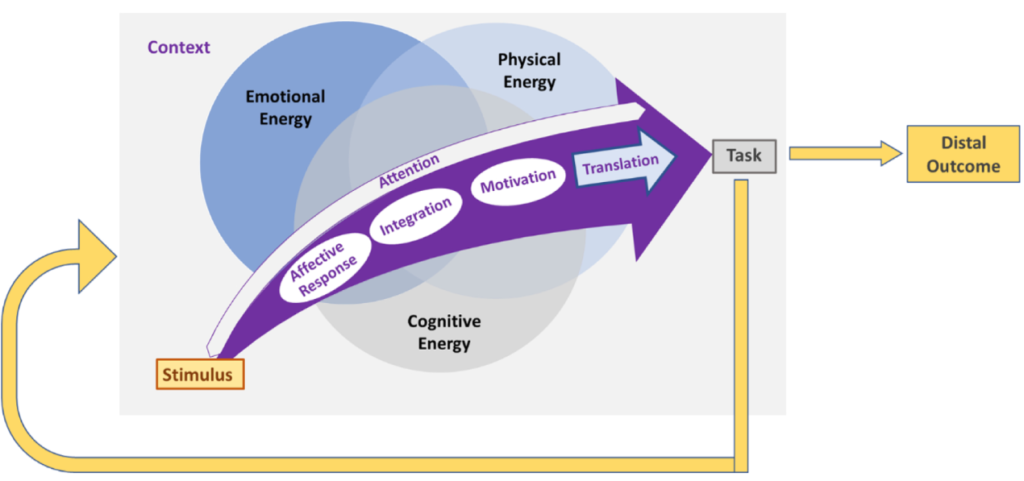
American Psychologist
March 17, 2022
engagement, digital interventions, affect, motivation, attention
The notion of “engagement,” which plays an important role in various domains of psychology, is gaining increased currency as a concept that is critical to the success of digital interventions. However, engagement remains an ill-defined construct, with different fields generating their own domain-specific definitions. Moreover, given that digital interactions in real-world settings are characterized by multiple demands and choice alternatives competing for an individual’s effort and attention, they involve fast and often impulsive decision making. Prior research seeking to uncover the mechanisms underlying engagement has nonetheless focused mainly on psychological factors and social influences and neglected to account for the role of neural mechanisms that shape individual choices. This paper aims to integrate theories and empirical evidence across multiple domains to define engagement and discuss opportunities and challenges to promoting effective engagement in digital interventions. We also propose the AIM-ACT framework, which is based on a neurophysiological account of engagement, to shed new light on how in-the-moment engagement unfolds in response to a digital stimulus. Building on this framework, we provide recommendations for designing strategies to promote engagement in digital interventions and highlight directions for future research.
This paper focuses on defining and understanding engagement in digital interventions by combining various theories and evidence from different domains. It introduces the AIM-ACT framework, which explains how engagement happens in response to digital stimuli based on neurophysiological principles and offers suggestions for designing effective engagement strategies in digital interventions.
Psychological Methods
January 13, 2022
December 2021
engagement, mobile health (mHealth), Micro-Randomized Trial (MRT), reciprocity, reinforcement
Contemporary Clinical Trials
engagement, Micro-randomized trial (MRT), mobile health (mHealth), self-regulatory strategies, smoking cessation
November 2021
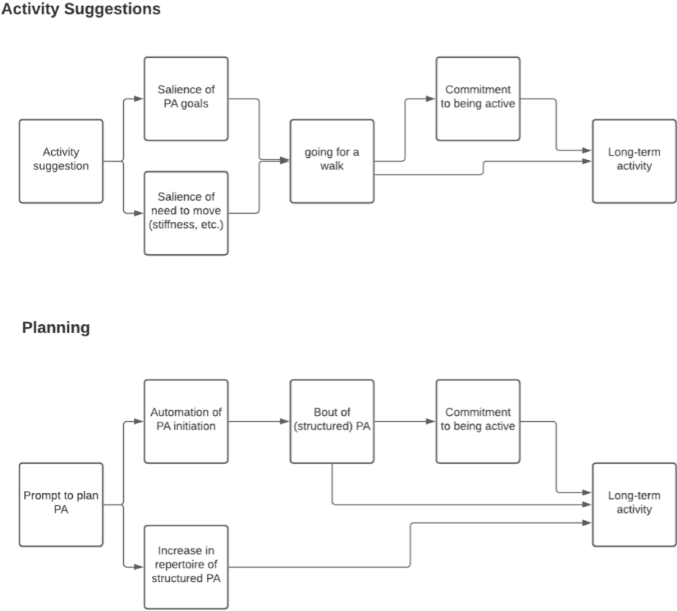
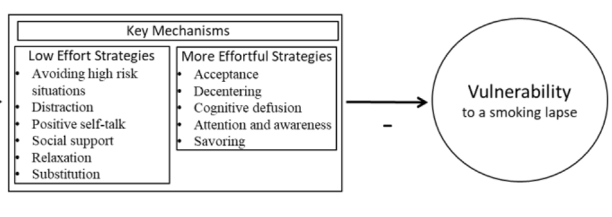
Smoking is the leading preventable cause of death and disability in the U.S. Empirical evidence suggests that engaging in evidence-based self-regulatory strategies (e.g., behavioral substitution, mindful attention) can improve smokers’ ability to resist craving and build self-regulatory skills. However, poor engagement represents a major barrier to maximizing the impact of self-regulatory strategies. This paper describes the protocol for Mobile Assistance for Regulating Smoking (MARS) – a research study designed to inform the development of a mobile health (mHealth) intervention for promoting real-time, real-world engagement in evidence-based self-regulatory strategies. The study will employ a 10-day Micro-Randomized Trial (MRT) enrolling 112 smokers attempting to quit. Utilizing a mobile smoking cessation app, the MRT will randomize each individual multiple times per day to either: (a) no intervention prompt; (b) a prompt recommending brief (low effort) cognitive and/or behavioral self-regulatory strategies; or (c) a prompt recommending more effortful cognitive or mindfulness-based strategies. Prompts will be delivered via push notifications from the MARS mobile app. The goal is to investigate whether, what type of, and under what conditions prompting the individual to engage in self-regulatory strategies increases engagement. The results will build the empirical foundation necessary to develop a mHealth intervention that effectively utilizes intensive longitudinal self-report and sensor-based assessments of emotions, context and other factors to engage an individual in the type of self-regulatory activity that would be most beneficial given their real-time, real-world circumstances. This type of mHealth intervention holds enormous potential to expand the reach and impact of smoking cessation treatments.
This paper describes the protocol for Mobile Assistance for Regulating Smoking (MARS) – a research study designed to inform the development of a mobile health (mHealth) intervention for promoting real-time, real-world engagement in evidence-based self-regulatory strategies.
Conference on Uncertainty in Artificial Intelligence (UAI 2023)
May 17, 2023
reinforcement learning, partial observability, context inference, adaptive interventions, empirical evaluation, mobile health
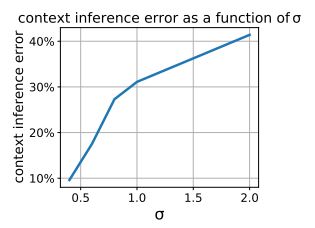
Just-in-Time Adaptive Interventions (JITAIs) are a class of personalized health interventions developed within the behavioral science community. JITAIs aim to provide the right type and amount of support by iteratively selecting a sequence of intervention options from a pre-defined set of components in response to each individual’s time varying state. In this work, we explore the application of reinforcement learning methods to the problem of learning intervention option selection policies. We study the effect of context inference error and partial observability on the ability to learn effective policies. Our results show that the propagation of uncertainty from context inferences is critical to improving intervention efficacy as context uncertainty increases, while policy gradient algorithms can provide remarkable robustness to partially observed behavioral state information.
This work focuses on JITAIs, personalized health interventions that dynamically select support components based on an individual’s changing state. The study applies reinforcement learning methods to learn policies for selecting intervention options, revealing that uncertainty from context inferences is crucial for enhancing intervention efficacy as context uncertainty increases.
arXiv:2308.07843
November 3, 2023
dyadic reinforcement learning, online learning, mobile health, algorithm design
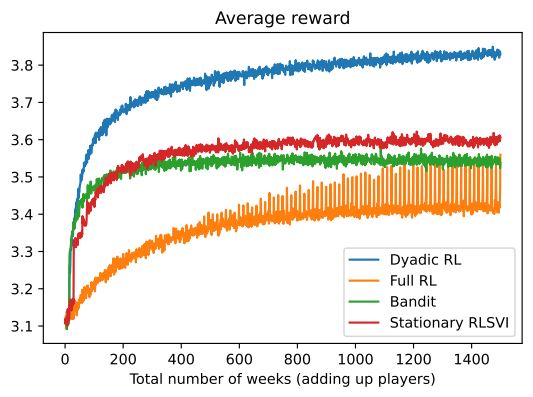
Mobile health aims to enhance health outcomes by delivering interventions to individuals as they go about their daily life. The involvement of care partners and social support networks often proves crucial in helping individuals managing burdensome medical conditions. This presents opportunities in mobile health to design interventions that target the dyadic relationship — the relationship between a target person and their care partner — with the aim of enhancing social support. In this paper, we develop dyadic RL, an online reinforcement learning algorithm designed to personalize intervention delivery based on contextual factors and past responses of a target person and their care partner. Here, multiple sets of interventions impact the dyad across multiple time intervals. The developed dyadic RL is Bayesian and hierarchical. We formally introduce the problem setup, develop dyadic RL and establish a regret bound. We demonstrate dyadic RL’s empirical performance through simulation studies on both toy scenarios and on a realistic test bed constructed from data collected in a mobile health study.
In this paper, we develop dyadic RL, an online reinforcement learning algorithm designed to personalize intervention delivery based on contextual factors and past responses of a target person and their care partner.

Digital Therapeutics for Mental Health and Addiction (pp.77-87)
just-in-time adaptive interventions, mental health, addiction
January 2023
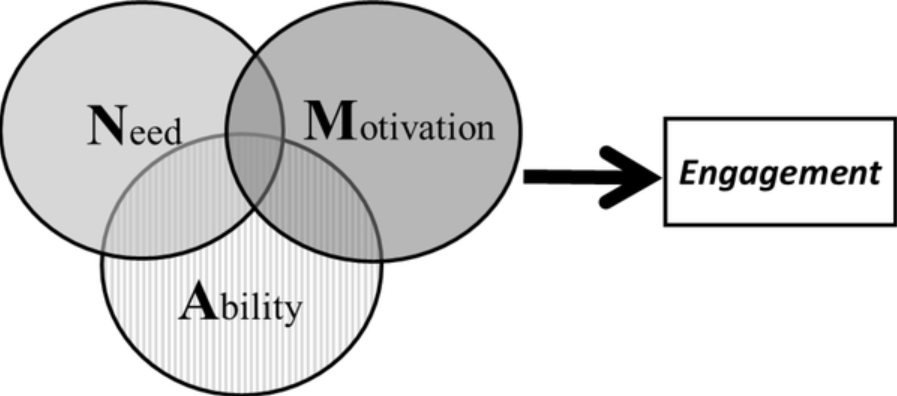
Advances in mobile and sensing technologies offer many opportunities for delivering just-in-time adaptive interventions (JITAIs)—interventions that use dynamically changing information about the individual’s internal state and context to recommend whether and how to deliver interventions in real-time, in daily life. States of vulnerability to an adverse outcome and states of receptivity to a just-in-time intervention play a critical role in the formulation of effective JITAIs. However, these states are defined, operationalized, and studied in various ways across different fields and research projects. This chapter is intended to (a) clarify the definition and operationalization of vulnerability to adverse outcomes and receptivity to just-in-time interventions; and (b) provide greater specificity in formulating scientific questions about these states. This greater precision has the potential to aid researchers in selecting the most suitable study design for answering questions about states of vulnerability and receptivity to inform JITAIs.
States of vulnerability to an adverse outcome and states of receptivity to a just-in-time intervention play a critical role in the formulation of effective JITAIs. This chapter is intended to clarify the definition and operationalization of vulnerability to adverse outcomes and receptivity to just-in-time interventions; and provide greater specificity in formulating scientific questions about these states.
Biometrika
binary outcome, causal excursion effect, causal inference, longitudinal data, micro-randomized trials, mobile health, relative risk, semiparametric efficiency theory
September 2021
We develop an estimator that can be used as the basis of a primary aim analysis under more plausible assumptions. Simulation studies are conducted to compare the estimators. We illustrate the developed methods using data from the MRT, BariFit. In BariFit, the goal is to support weight maintenance for individuals who received bariatric surgery.
Contemporary Clinical Trials
digital intervention, just-in-time adaptive intervention, micro-randomized trial, optimization, smoking, stress, mHealth
August 8, 2021
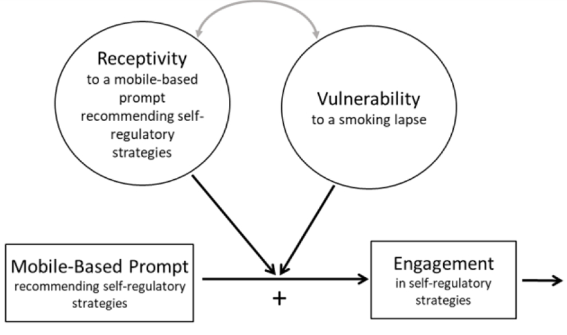
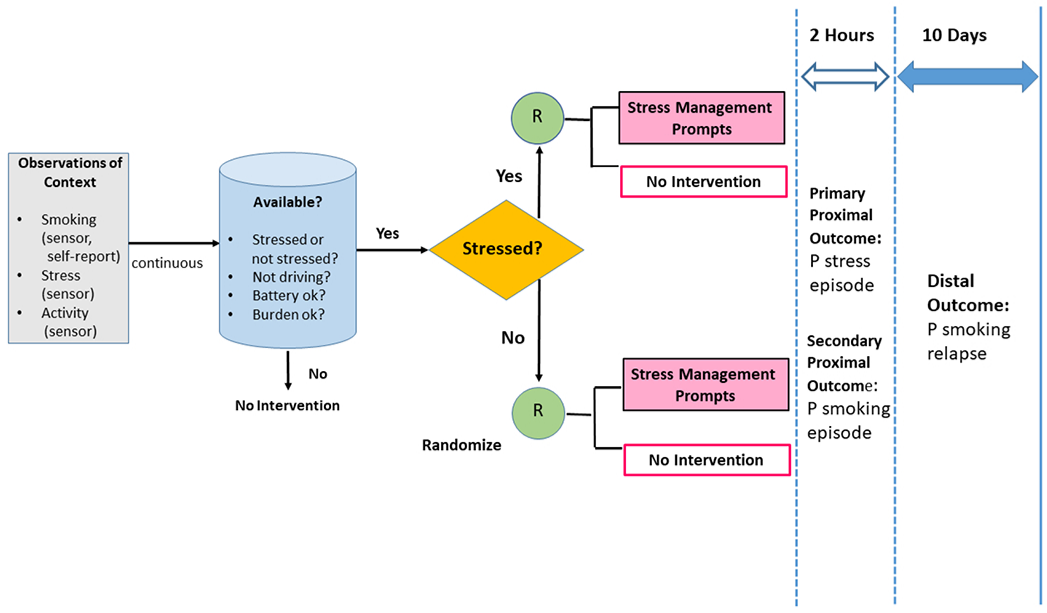
Background: Relapse to smoking is commonly triggered by stress, but behavioral interventions have shown only modest efficacy in preventing stress-related relapse. Continuous digital sensing to detect states of smoking risk and intervention receptivity may make it feasible to increase treatment efficacy by adapting intervention timing.
Objective: Aims are to investigate whether the delivery of a prompt to perform stress management behavior, as compared to no prompt, reduces the likelihood of (a) being stressed and (b) smoking in the subsequent two hours, and (c) whether current stress moderates these effects.
Study Design: A micro-randomized trial will be implemented with 75 adult smokers who wear Autosense chest and wrist sensors and use the mCerebrum suite of smartphone apps to report and respond to ecological momentary assessment (EMA) questions about smoking and mood for 4 days before and 10 days after a quit attempt and to access a set of stress-management apps. Sensor data will be processed on the smartphone in real time using the cStress algorithm to classify minutes as probably stressed or probably not stressed. Stressed and non-stressed minutes will be micro-randomized to deliver either a prompt to perform a stress management exercise via one of the apps or no prompt (2.5-3 stress management prompts will be delivered daily). Sensor and self-report assessments of stress and smoking will be analyzed to optimize decision rules for a just-in-time adaptive intervention (JITAI) to prevent smoking relapse.
Significance: Sense2Stop will be the first digital trial using wearable sensors and micro-randomization to optimize a just-in-time adaptive stress management intervention for smoking relapse prevention.
Sense2Stop will be the first digital trial using wearable sensors and micro-randomization to optimize a just-in-time adaptive stress management intervention for smoking relapse prevention.

Bonnie Spring, Inbal Nahum-Shani, Samuel L Battalio, David E Conroy, Walter Dempsey, Elyse Daly, Sara A Hoffman, Timothy Hnat, Susan Murphy, Marianne Menictas, Shahin Samiei, Tianchen Qian, Jamie Yapp, Santosh Kumar,
ANNALS OF BEHAVIORAL MEDICINE, Vol 57
April 1, 2023
About this code
This example code calculates the minimum sample size for Sense2Stop, a 10-day, stratified micro-randomized trial. Study participants wear a chest and wrist band sensors that are used to construct a binary, time-varying stress classification at each minute of the day. The intervention is a smartphone notification to remind the participant to access a smartphone app and practice stress-reduction exercises. Intervention delivery is constrained to limit participant burden (a limit on the number of reminders sent) and to times at which the sensor-based stress classification is possible. The trial was designed to answer the questions: “Is there an effect of the reminder on near-term, proximal stress if the individual is currently experiencing stress? And, does the effect of the reminder vary with time in study?”
How can a behavioral scientist use this code?
Behavioral intervention scientists can use this code as a starting point for calculating the sample size and power for micro-randomized trials that are similar to the Sense2Stop study.
What method does this code implement?
The code is based on a novel method that (i) balances small sample bias and power, (ii) avoids causal bias, and (iii) informs the expected number of episodes during the remaining part of the day that will be classified as stressed versus not stressed using a generative model (that is based on prior observational study data). Note that the code was developed to be specific to the design of the Sense2Stop study. Significant modification may potentially be needed should this code be used as a starting point to calculate sample size in studies whose design have significant departures from the Sense2Stop study design.
Contemporary Clinical Trials
Volume 145
October 2024
Just-in-Time Adaptive Interventions, mHealth, cannabis use, emerging adults, micro-randomized trial, reinforcement learning, mobile app-based intervention.
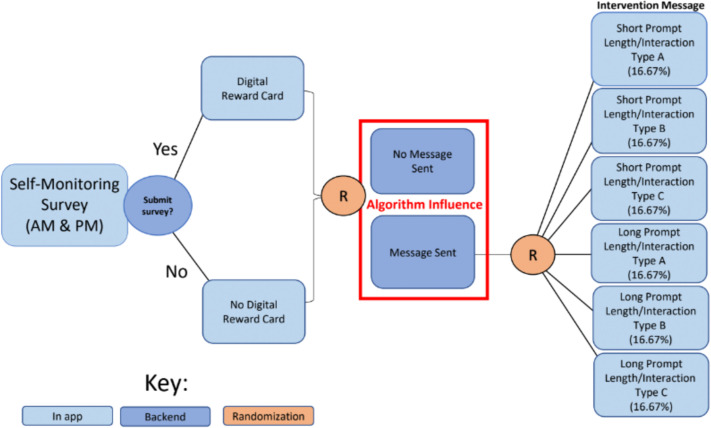
Emerging adult (EA) cannabis use is associated with increased risk for health consequences. Just-in-time adaptive interventions (JITAIs) provide potential for preventing the escalation and consequences of cannabis use. Powered by mobile devices, JITAIs use decision rules that take the person’s state and context as input, and output a recommended intervention (e.g., alternative activities, coping strategies). The mHealth literature on JITAIs is nascent, with additional research needed to identify what intervention content to deliver when and to whom. Herein we describe the protocol for a pilot study testing the feasibility and acceptability of a micro-randomized trial for optimizing MiWaves mobile intervention app for EAs (ages 18–25; target N = 120) with regular cannabis use (≥3 times per week). Micro-randomizations will be determined by a reinforcement learning algorithm that continually learns and improves the decision rules as participants experience the intervention. MiWaves will prompt participants to complete an in-app twice-daily survey over 30 days and participants will be micro-randomized twice daily to either: no message or a message [1 of 6 types varying in length (short, long) and interaction type (acknowledge message, acknowledge message + click additional resources, acknowledge message + fill in the blank/select an option)]. Participants recruited via social media will download the MiWaves app, and complete screening, baseline, weekly, post-intervention, and 2-month follow-up assessments. Primary outcomes include feasibility and acceptability, with additional exploratory behavioral outcomes. This study represents a critical first step in developing an effective mHealth intervention for reducing cannabis use and associated harms in EAs.
mHealth app uses reinforcement learning in a micro-randomized trial to deliver personalized interventions aiming to reduce cannabis use in emerging adults.
(In Press) Annual Review of Psychology – Vol. 77 (2026)
Forthcoming 2026
Reinforcement Learning (RL), Personalized Interventions, Just-in-Time Adaptive Interventions (JITAIs), Public Health.
Forthcoming
Forthcoming 2026
Contemporary Clinical Trials
engagement, Micro-randomized trial (MRT), mobile health (mHealth), self-regulatory strategies, smoking cessation
November 2021
Smoking is the leading preventable cause of death and disability in the U.S. Empirical evidence suggests that engaging in evidence-based self-regulatory strategies (e.g., behavioral substitution, mindful attention) can improve smokers’ ability to resist craving and build self-regulatory skills. However, poor engagement represents a major barrier to maximizing the impact of self-regulatory strategies. This paper describes the protocol for Mobile Assistance for Regulating Smoking (MARS) – a research study designed to inform the development of a mobile health (mHealth) intervention for promoting real-time, real-world engagement in evidence-based self-regulatory strategies. The study will employ a 10-day Micro-Randomized Trial (MRT) enrolling 112 smokers attempting to quit. Utilizing a mobile smoking cessation app, the MRT will randomize each individual multiple times per day to either: (a) no intervention prompt; (b) a prompt recommending brief (low effort) cognitive and/or behavioral self-regulatory strategies; or (c) a prompt recommending more effortful cognitive or mindfulness-based strategies. Prompts will be delivered via push notifications from the MARS mobile app. The goal is to investigate whether, what type of, and under what conditions prompting the individual to engage in self-regulatory strategies increases engagement. The results will build the empirical foundation necessary to develop a mHealth intervention that effectively utilizes intensive longitudinal self-report and sensor-based assessments of emotions, context and other factors to engage an individual in the type of self-regulatory activity that would be most beneficial given their real-time, real-world circumstances. This type of mHealth intervention holds enormous potential to expand the reach and impact of smoking cessation treatments.
This paper describes the protocol for Mobile Assistance for Regulating Smoking (MARS) – a research study designed to inform the development of a mobile health (mHealth) intervention for promoting real-time, real-world engagement in evidence-based self-regulatory strategies.

arXiv preprint: 2402.17739
June 11, 2024
reBandit, Reinforcement Learning (RL), Mobile Health (mHealth), Cannabis Use Disorder (CUD), Emerging Adults (EAs), Personalized Interventions, Random Effects, Bayesian Priors, Online Algorithm, Just-in-Time Adaptive Interventions (JITAIs), Simulation, Public Health.
The escalating prevalence of cannabis use, and associated cannabis-use disorder (CUD), poses a significant public health challenge globally. With a notably wide treatment gap, especially among emerging adults (EAs; ages 18-25), addressing cannabis use and CUD remains a pivotal objective within the 2030 United Nations Agenda for Sustainable Development Goals (SDG). In this work, we develop an online reinforcement learning (RL) algorithm called reBandit which will be utilized in a mobile health study to deliver personalized mobile health interventions aimed at reducing cannabis use among EAs. reBandit utilizes random effects and informative Bayesian priors to learn quickly and efficiently in noisy mobile health environments. Moreover, reBandit employs Empirical Bayes and optimization techniques to autonomously update its hyper-parameters online. To evaluate the performance of our algorithm, we construct a simulation testbed using data from a prior study, and compare against commonly used algorithms in mobile health studies. We show that reBandit performs equally well or better than all the baseline algorithms, and the performance gap widens as population heterogeneity increases in the simulation environment, proving its adeptness to adapt to diverse population of study participants.
This paper introduces reBandit, an online reinforcement learning (RL) algorithm designed to reduce cannabis use among emerging adults (ages 18-25) through personalized mobile health (mHealth) interventions. reBandit is built to learn quickly and efficiently in noisy mHealth environments by utilizing random effects and informative Bayesian priors, which allow it to both personalize treatments for individual users and leverage data from the broader population. The algorithm also autonomously updates its hyper-parameters online and is engineered to account for delayed effects of interventions. Simulations show that reBandit performs equally well or better than other common mHealth algorithms, with its performance advantage increasing as population heterogeneity rises.
Lecture Notes in Computer Science (LNAI,volume 15734)
International Conference on Artificial Intelligence in Medicine
June 23, 2025
reBandit, Reinforcement Learning (RL), Mobile Health (mHealth), Cannabis Use Disorder (CUD), Emerging Adults (EAs), Personalized Interventions, Random Effects, Bayesian Priors, Online Algorithm, Just-in-Time Adaptive Interventions (JITAIs), Simulation, Public Health.
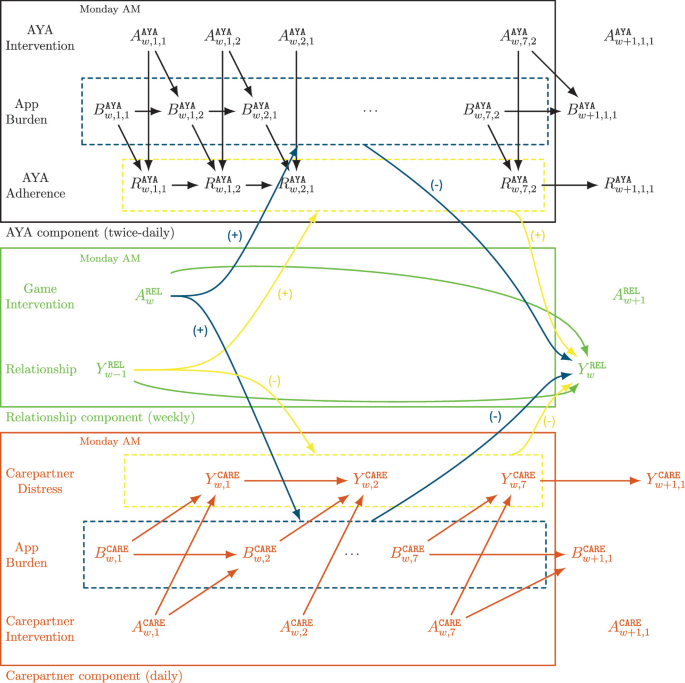
Medication adherence is critical for the recovery of adolescents and young adults (AYAs) who have undergone hematopoietic cell transplantation. However, maintaining adherence is challenging for AYAs after hospital discharge, who experience both individual (e.g. physical and emotional symptoms) and interpersonal barriers (e.g., relational difficulties with their care partner, who is often involved in medication management). To optimize the effectiveness of a three-component digital intervention targeting both members of the dyad as well as their relationship, we propose a novel Multi-Agent Reinforcement Learning (MARL) approach to personalize the delivery of interventions. By incorporating the domain knowledge, the MARL framework, where each agent is responsible for the delivery of one intervention component, allows for faster learning compared with a flattened agent. Evaluation using a dyadic simulator environment, based on real clinical data, shows a significant improvement in medication adherence (approximately 3%) compared to purely random intervention delivery. The effectiveness of this approach will be further evaluated in an upcoming trial.
This publication introduces a novel Multi-Agent Reinforcement Learning (MARL) approach to personalize the delivery of a three-component digital intervention (ADAPTS-HCT) aimed at improving medication adherence in adolescents and young adults (AYAs) who have undergone hematopoietic cell transplantation (HCT) and their care partners. The MARL framework, which assigns separate agents to the AYA, care partner, and relationship components, addresses challenges like multi-scale decision-making and noisy, data-limited settings by incorporating domain knowledge and using surrogate reward functions. Evaluation in a simulated dyadic environment, based on real clinical data, demonstrated a significant improvement of approximately 3% in medication adherence compared to purely random intervention delivery, with further evaluation planned in an upcoming clinical trial.
August 16, 2025
Large Language Models, Adaptive Behavioral Interventions, Reinforcement Learning, Personalization, Natural Language Processing, Digital Health.
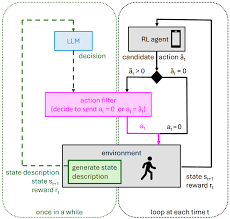
Code for "Designing Reinforcement Learning Algorithms for Digital Interventions: Pre-implementation Guidelines" Paper
https://github.com/StatisticalReinforcementLearningLab/pcs-for-rl
0 forks.
2 stars.
0 open issues.
Recent commits:
Algorithms in Decision Support Systems
July 22, 2022
Python
Code to reproduce results for "Statistical Inference with M-Estimators on Adaptively Collected Data"
https://github.com/kellywzhang/adaptively_weighted_Mestimation
2 forks.
1 stars.
0 open issues.
Recent commits:
Advances in Neural Information Processing Systems
December 2021
Python
Shell
The material in this repository is a supplement to the manuscript titled `The Mobile-Assistance for Regulating Smoking (MARS) Micro-Randomized Trial Design Protocol' (Nahum-Shani, et al., 2021), submitted for consideration to the Journal of Contemporary Clinical Trials. The material include code and documentation for the power calculation for the Primary Aim and Secondary Aim of the trial.
https://github.com/jamieyap/power-calc-mars-mrt
1 forks.
0 stars.
0 open issues.
Recent commits:
Contemporary Clinical Trials
November 2021
R
RL for JITAI optimization using simulated environments.
https://github.com/reml-lab/rl_jitai_simulation
1 forks.
1 stars.
0 open issues.
Recent commits:
arXiv:2308.07843
November 3, 2023
Python
R
Shell
https://github.com/mDOT-Center/pJITAI
3 forks.
1 stars.
44 open issues.
Recent commits:
The pJITAI toolbox being developed in TR&D2 software and code repository. The repository serves as a centralized hub for storing, managing, and tracking the evolution of project code, scripts, and software tools. This facilitates seamless collaboration among project members, streamlining the process of code integration, debugging, and enhancement. The repository’s branching and versioning capabilities enable the team to work concurrently on different aspects of the project without compromising code integrity. It ensures that changes are tracked, reviewed, and merged in a controlled manner, bolstering the project’s overall reliability.
Mobile health (mHealth) interventions have typically used hand-crafted decision rules that map from biomarkers of an individual’s state to the selection of interventions. Recently, reinforcement learning (RL) has emerged as a promising approach for online optimization of decision rules. Continuous, passive detection of the individual’s state using mHealth biomarkers enables dynamic deployment of decision rules at the right moment, i.e., as and when events of interest are detected from sensors. RL-based optimization methods that leverage this new capability created by sensor-based biomarkers, can enable the development and optimization of temporally-precise mHealth interventions, overcoming the significant limitations of static, one-size-fits-all decision rules. Such next generation interventions have the potential to lead to greater treatment efficacy and improved long-term engagement.
However, there exist several critical challenges to the realization of effective, real-world RL-based interventions including the need to learn efficiently based on limited interactions with an individual while accounting for longer-term effects of intervention decisions, (i.e., to avoid habituation and ensure continued engagement), and accommodating multiple intervention components operating at different time scales and targeting different outcomes. As a result, the use of RL in mHealth interventions has mostly been limited to very few studies using basic RL methods.
To address these critical challenges, TR&D2 builds on more precise biomarkers of context, including TR&D1 risk and engagement scores, to develop, evaluate, and disseminate robust and data efficient RL methods and tools. These methods continually personalize the selection, adaptation and delivery timing decision rules for core intervention components so as to maximize long-term therapeutic efficacy and engagement for every individual.
















Assistant Professor

Applied Scientist II

Senior Research Scientist

Applied Scientist
Presentations by Susan Murphy
Presentations by Raaz Dwivedi (postdoctoral researcher)
Presentation by Kyra Gan (postdoctoral researcher)
Presentation by Shuangning Li (postdoctoral researcher)
Presentations by Kelly Zhang (graduate student)
Presentations by Anna Trella (graduate student)
Presentations by Xiang Meng (graduate student)
Presentation by Prasidh Chhabria (undergraduate student)

TR&D2 Lead

Lead PI, Center Director, TR&D1, TR&D2, TR&D3

Co-Investigator, TR&D1, TR&D2

Doctoral Student

Doctoral Student

Doctoral Student

Doctoral Student
Research and development by TR&D2 will significantly advance RL methodology for personalizing decision rules; in particular, with regards to online algorithms that personalize interventions for each user by appropriately pooling across multiple users.
