CP2, a collaborative project involving industry (P&G, Delta Dental), will remotely monitor Oral Health Behaviors (OHBs) in the home setting and use the insights to develop a computationally-driven, personalized Digital Oral Health Intervention (DOHIs) and test its real-world efficacy in engaging at-risk individuals in ideal OHBs and improving their oral health. CP2 builds on the Remote Oral Behavior Assessment System project (ROBAS; 1R01DE025244; NIH/NIDCR; 7/1/15–5/31/20: PI: Shetty) that provides objective, individual-level and ecologically-valid data on oral hygiene behaviors.
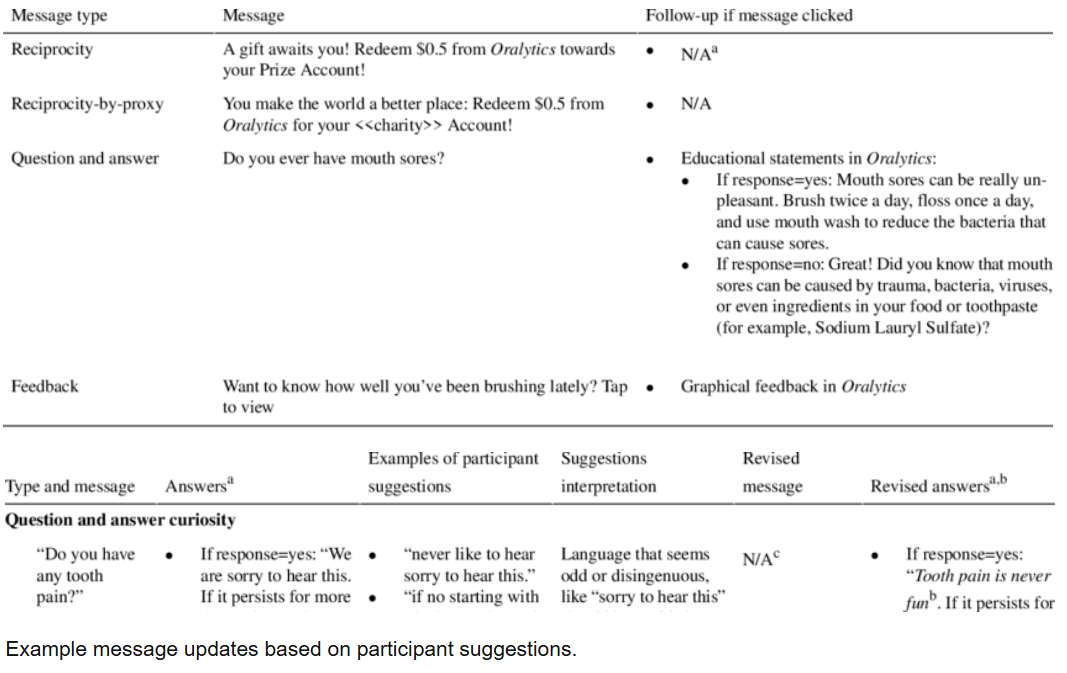
In the preparatory UG3 phase, CP2 will engage end-users in the co-design of an oral self-care app and establish the usability and feasibility of the system. In the UH3 phase, CP2 will build and validate computational models for inferring the quality of OHBs and for tailoring of the DOHI. Using a cohort of 130 subjects, CP2 will conduct a 10-week Micro-Randomized Trial (MRT) to optimize the adaptive tailoring of the engagement strategies for the DOHI. Finally, CP2 will test its hypothesis (that the dynamic and personalized DOHI will be more effective than traditional, static, clinician-delivered OHI in improving oral health and adherence to 2x2x4 OHBs (brush 2 times a day, for 2 minutes each time, all 4 dental quadrants)) through a 6-month, pragmatic, randomized, controlled, parallel-group clinical trial of 260 subjects.
CP2 can fundamentally alter oral healthcare, emphasizing prevention and oral health maintenance. Beyond advancing behavior change theories, linking dental disease to actual OHBs would enhance our understanding of dental disease determinants and establish which digital behavioral intervention may be most effective, when and for whom, providing a springboard to the practice of 21st century temporally-precise dentistry.
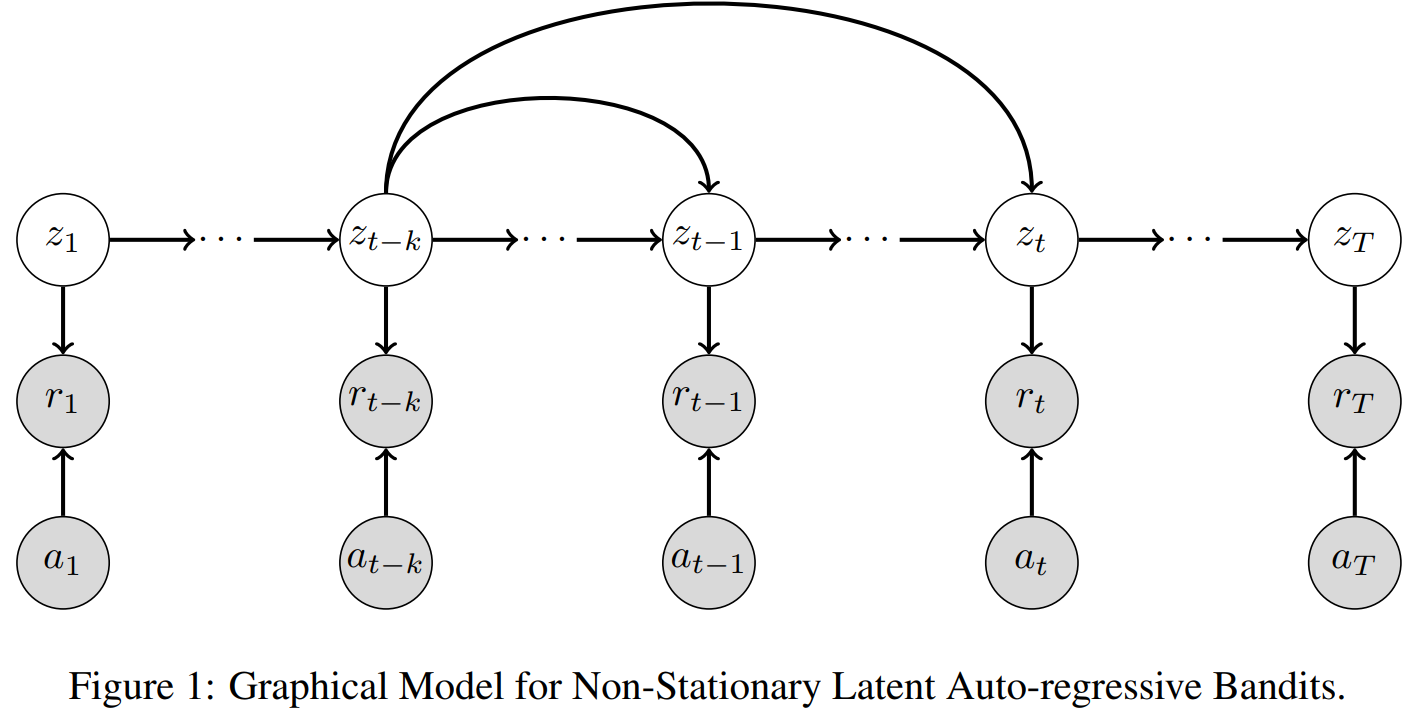
CP2 is developing digital biomarkers of brushing from consumer toothbrushes and wearable wrist. To analyze the time series of OHB biomarkers from its studies, CP2 will leverage tools developed by TR&D1 Aim 1 to characterize the uncertainty in its biomarkers. In collaboration with TR&D1 Aim 2, CP2 will develop a dynamic risk indicator for dental disease which will support future intervention development. Successful data collection over six months requires enough engagement so participants can continue to be interested in the study. TR&D1 will work with CP2 to develop an score of engagement and TR&D2 will work with CP2 to identify strategies for improving engagement from the data collected so that future such studies can achieve greater compliance from their participants over long-term. Next, CP2 will utilize modeling tools from TR&D1 Aim 3 to model the dynamic relationships among the sociobehavioral risk factors captured by digital biomarkers of OHBs, eating, stress, activity, location, and mobility. Multiple iterations of model development, evaluation on study data, and refinement with domain experts will ensure that TR&D1 methods advance CP2 research on temporally-precise dentistry.
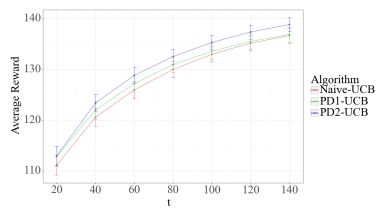
In push/pull collaboration with TR&D2, CP2 will develop DOHI intervention decision rules based on data from the 10-week Micro-Randomized Trial (MRT). In the RL framework, the actions are engagement strategies and the near time rewards is daily engagement in the 2x2x4 OHBs. The MRT will also provide data for TR&D2 to develop useful simulations for early evaluations of the methods under Aims 1 and 2. TR&D2 will provide a RL personalization algorithm (based on work under Aims 1 and 2) that uses the above decision rules as a warm start to personalize these decision rules as an individual experiences the DOHI intervention. CP2 is interested in deploying the developed RL algorithm in real-time to personalize decision rules for a small additional number of subjects in the 6-month trial; this deployment will provide data on real-time feasibility and acceptability from subjects as they experience the RL algorithm. The 6-month trial will also provide data to build a testbed simulation for use by TR&D2 to conduct early evaluation of the methods under Aim 3.
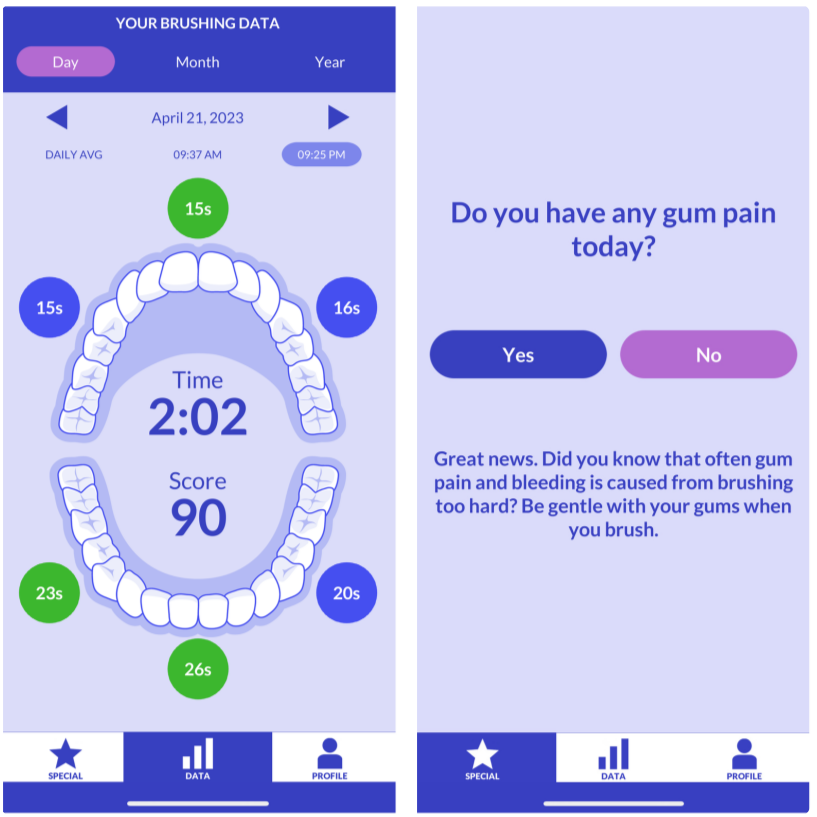
Currently, OHB biomarkers are being implemented in a cloud platform, after data collection. TR&D3 Aim 1 will work with CP2 to design, develop and validate micromarkers for real-time detection of OHB’s on smartphones from wrist and brush sensors. These new biomarkers will then become easily usable by researchers deploying wrist-worn sensors and in common consumer devices (e.g., Oral-B). In addition, integrating information across the sensors embedded into the toothbrush and wristband will provide unique insight on how the subjects hold and use their toothbrush. For this purpose, CP2 will test and deploy distributed fusion of information from two high rate inertial sensors at high time resolution from Aim 2. The UG3 will provide rapid feedback on the usability and utility of TR&D1 sensors and methods, which will be evaluated in the UH3 phase of CP2.









No Comments