The mDOT Center
Transforming health and wellness via temporally-precise mHealth interventions






mDOT@MD2K.org
901.678.1526
901.678.1526


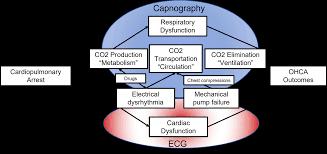
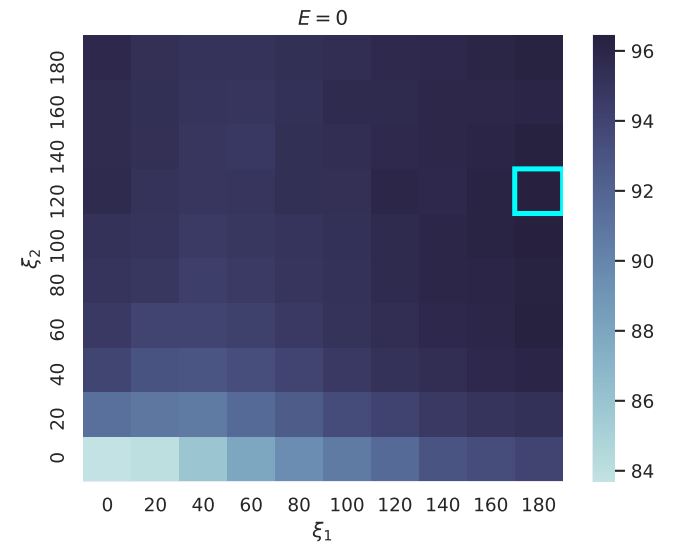
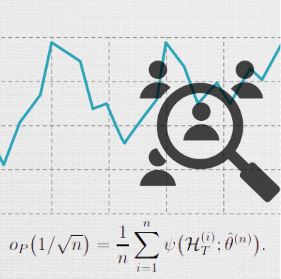
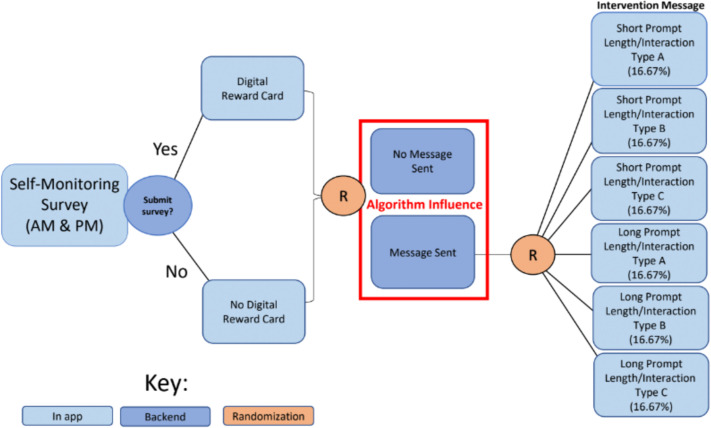

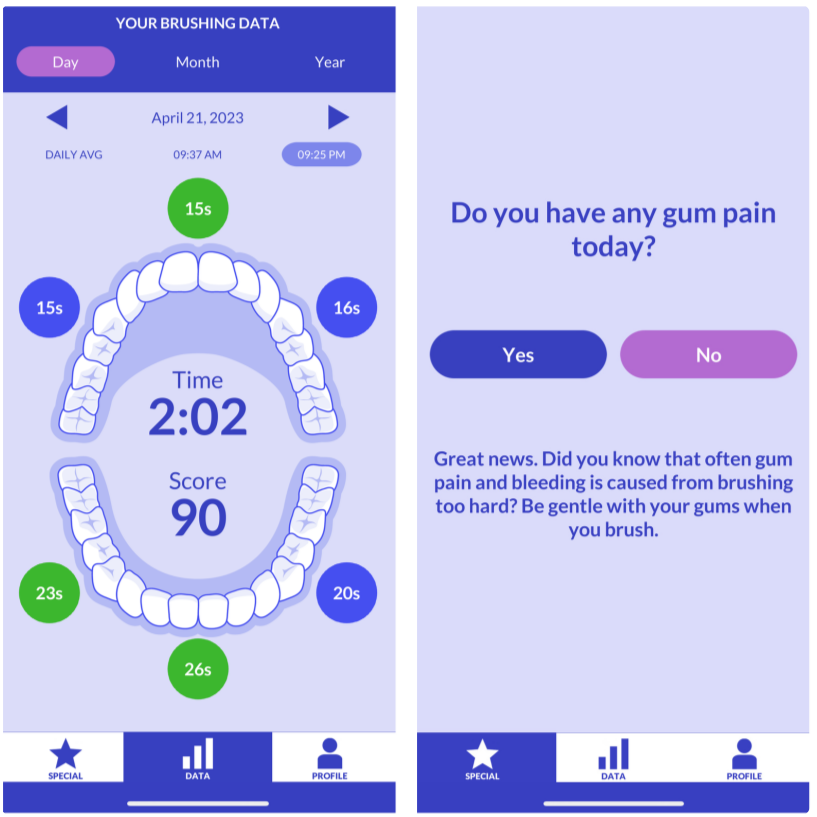
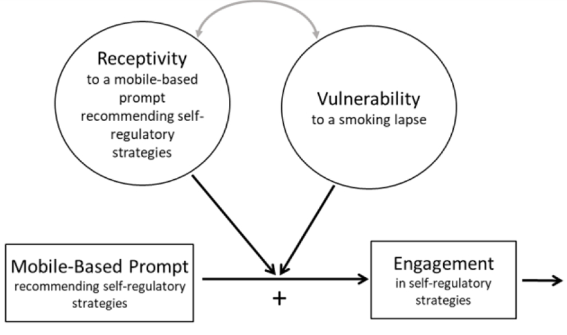
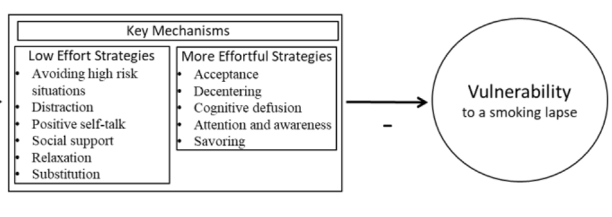
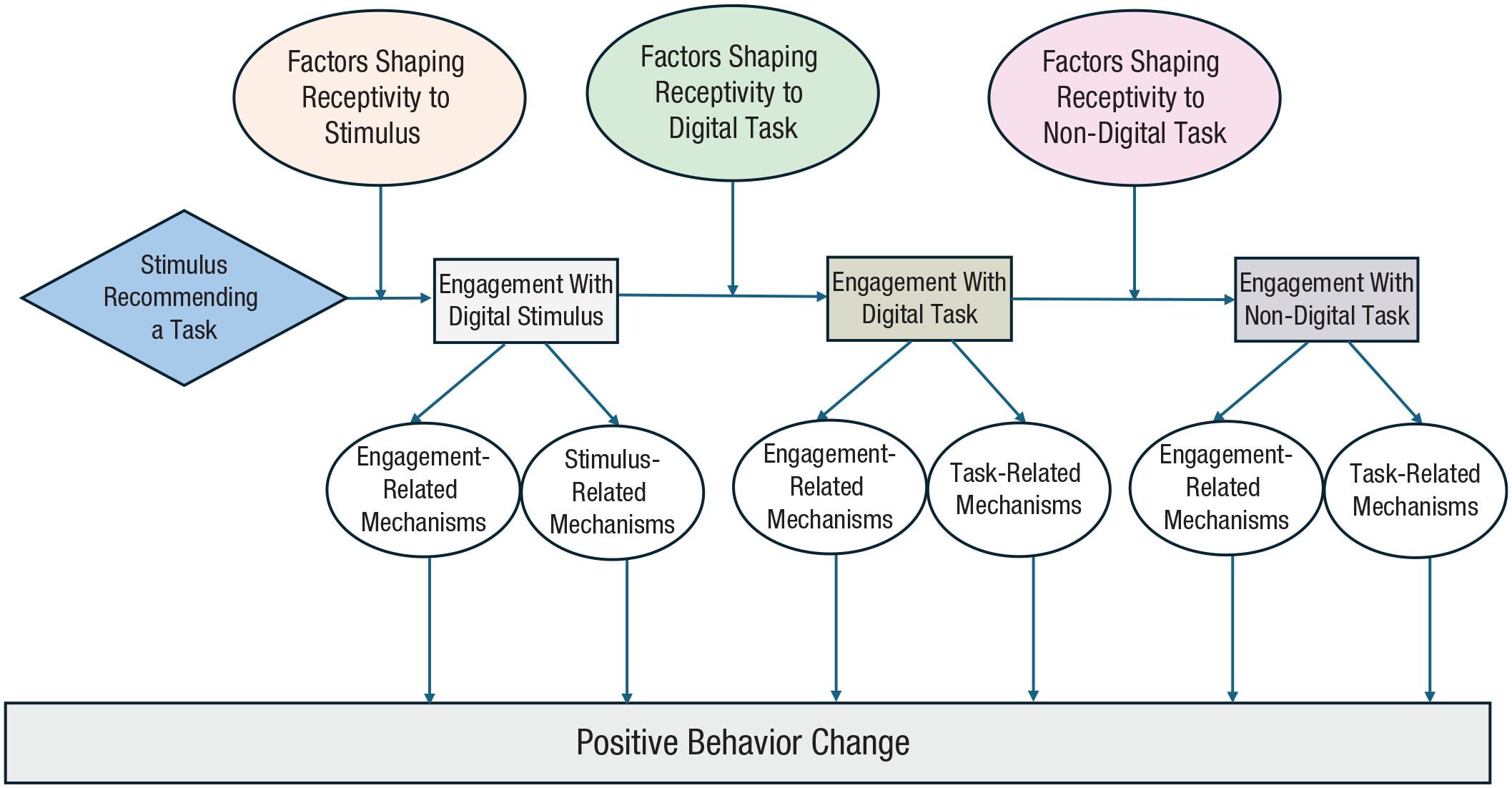
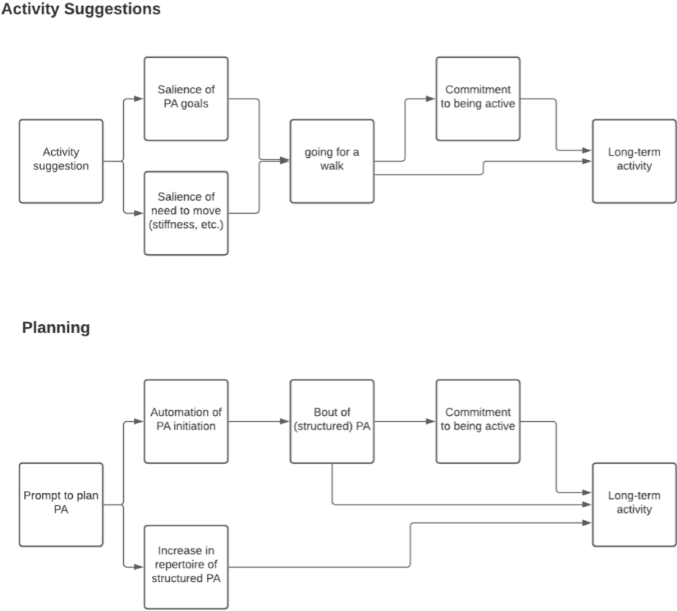
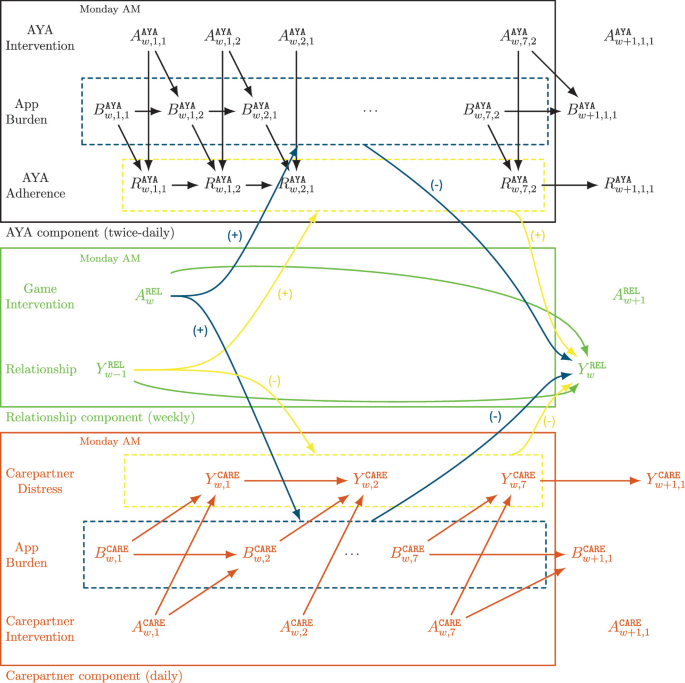

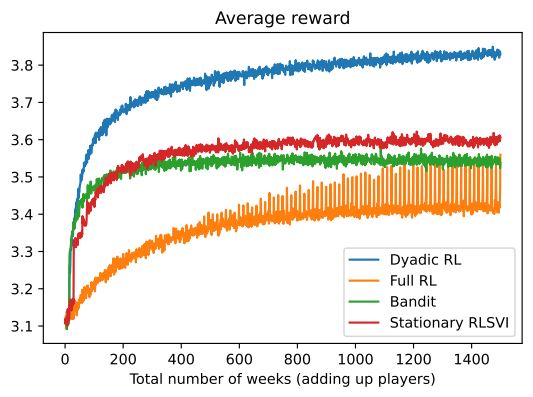
The focus of the MAPS Center is the development, evaluation, and dissemination of novel research methodologies that are essential to optimize adaptive interventions to combat SUD/HIV. Project 2 focuses on developing innovative methods that will enable scientists, for the first time, to optimize the integration of human-delivered services with relatively low-intensity adaptation (i.e., adaptive interventions) and digital services with high-intensity adaptation (i.e., JITAIs). This project will develop a new trial design in which individuals can be randomized simultaneously to human-delivered and digital interventions at different time scales. This includes developing guidelines for trial design, sample size calculators, and statistical analysis methods that will enable scientists to use data from the new experimental design to address novel questions about synergies between human-delivered adaptive interventions and digital JITAIs. Project 3 focuses on developing innovative methods to optimize JITAIs in which the decision rules are continually updated to ensure effective adaptation as individual needs change and societal trends occur. Integrating approaches from artificial intelligence and statistics, this project will develop algorithms that continually update “population-based” decision rules (designed to work well for all individuals on average) to improve intervention effectiveness. This project will also generalize these algorithms to continually optimize “person-specific” decision rules for JITAIs. The algorithms will be designed specifically to (a) assign each individual the intervention that is right for them at a particular moment; (b) maintain acceptable levels of burden; and (c) maintain engagement.
Project 3 of MAPS aims to collaborate with TR&D2 (Murphy) by developing methods for appropriately pooling of data from multiple users to speed up learning of both population-based decision rules as well as personalized decision rules. These collaborations will used to enhance the impact of TR&D2’s Aims 2 and 3 and thus lay the foundation for successful future research projects. Project 3 of MAPS aims to collaborate with TR&D1 (Marlin) by utilizing advances by TR&D1 in propagating and representing uncertainty in Project 3’s development of methods for adapting the timing and location of delivery of different intervention prompts. These collaborations will increase the impact of TR&D1’s Aims 1 and 2. Project 2 of MAPS plans to collaborate with TR&D1 (Marlin) to develop a composite substance use risk indicator derived from sensor data that can be assessed at different time scales and hence can inform the adaptation of both human-delivered and digital interventions; and to collaborate with TR&D2 (Murphy) to develop optimization methods for learning what type and under what conditions digital interventions are best delivered in a setting in which non-digital interventions (human-delivered interventions) are also provided– this is an extreme case of TR&D2’s Aim 3 focused on multiple intervention components delivered at different time scales and with different short-term objectives. As such this collaboration has the potential to synergistically enhance both TR&D’s as well as MAP’s Project 2 aims.
CP, Drug Use, HIV, TR&D1, TR&D2
You must be logged in to post a comment.
No Comments