The mDOT Center
Transforming health and wellness via temporally-precise mHealth interventions






mDOT@MD2K.org
901.678.1526
901.678.1526


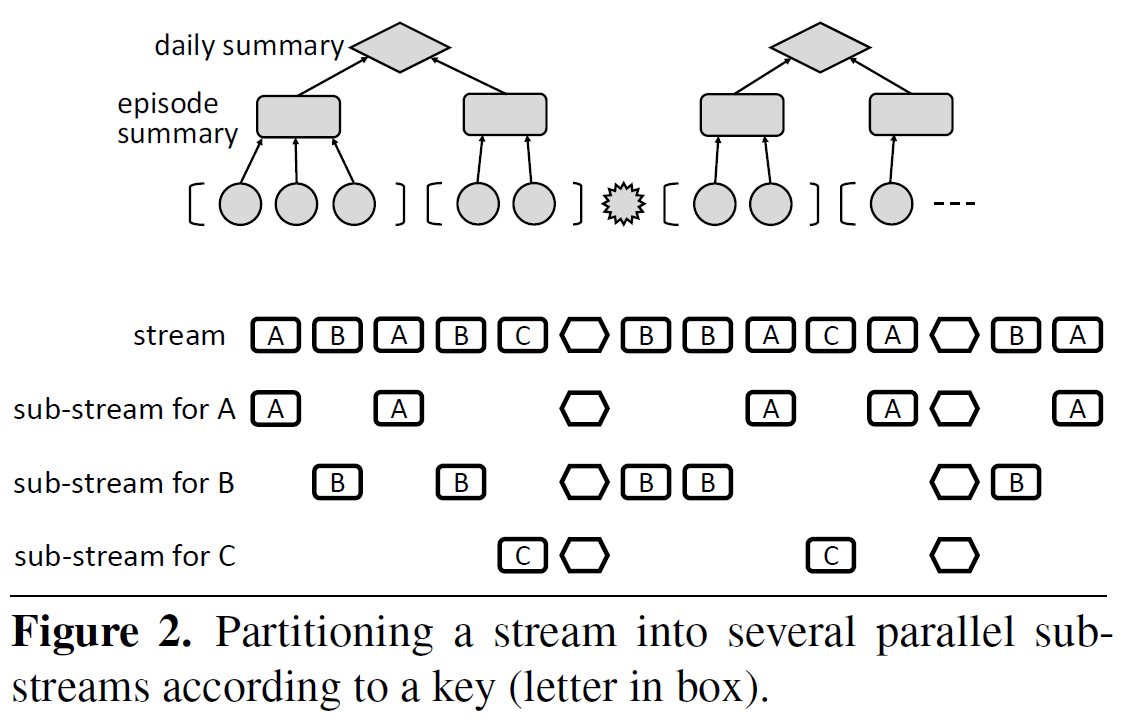
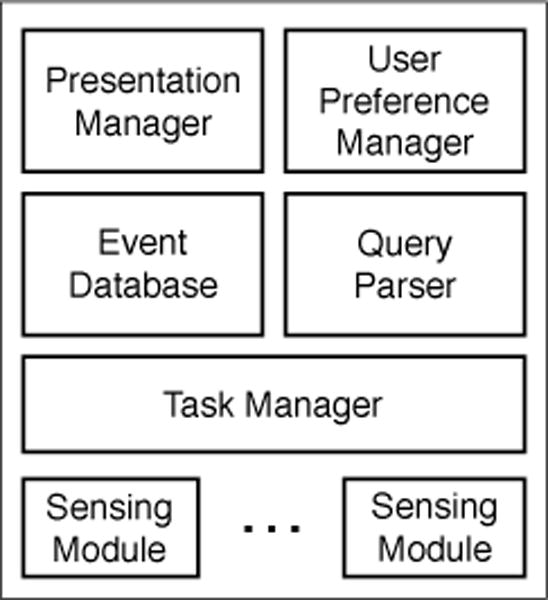

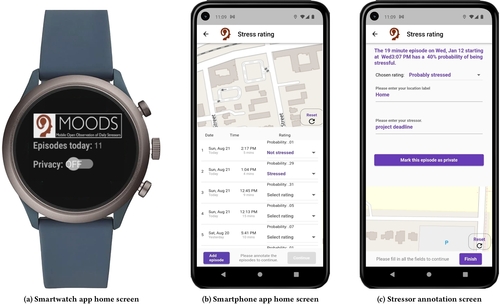
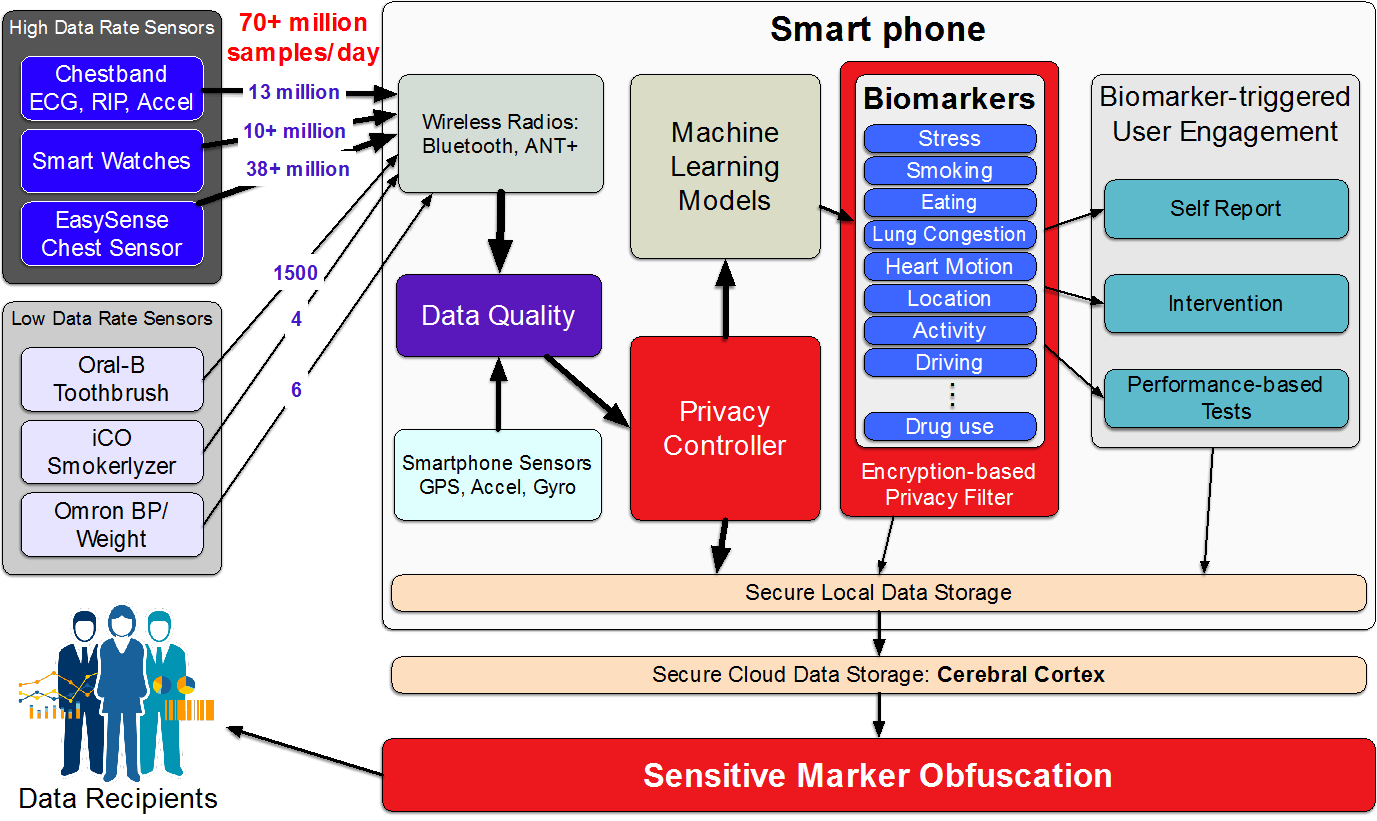
There are major hurdles to using mobile sensor data to advance research on computational modeling of human health and behavior, including lack of access to high-quality mobile sensor data, regulatory obligations in accessing and using mobile sensor data collected from humans, and a lack of metadata capture and access services for the provenance, quality, and integrity of the data and inferences made from it. CP7 is developing a new cyberinfrastructure called mProv to annotate high-frequency mobile sensor data with data source, quality, validity, and semantics to facilitate the sharing of such data with the wider research community for third party research. It is developing techniques to integrate metadata and data capture over mobile streaming data, and propagate such data in order to enable reasoning about uncertainty and variability; runtime infrastructure and APIs for efficient sensor data acquisition and reply (integrated with human data capture), and mechanisms for managing privacy policies. To support interpretation of sensor-derived features and inferences (i.e., markers of health, behavior, and context) by researchers (for concurrent development that makes use of datastreams developed by other researchers) and automating analysis by machines, CP7 has developed datastream representation to support a common metadata structure that allows both mCerebrum and Cerebral Cortex (installed on mobile phones and the cloud respectively) to annotate the datastream with metadata. It has also developed storage, interface, instrumentation, and visualization tools for provenance tracking through stream processing operators. Provenance information can be automatically captured as a series of entities, activities, and relationships in a graph database from which it can be queried or visualized, even in near-real-time. It has built a core provenance repository with user authentication, group creation, and metadata storage capabilities. These are exposed through a simple REST microservices framework, and they can be retargeted at the back-end to a variety of SQL and NoSQL database systems. Currently, CP7 software uses Cassandra, REDIS, Neo4J, and Postgres. CP7 also works closely with an R24 from NIBIB (R24EB025845; PI: Ida Sim, UC San Francisco; 7/1/17-6/30/20) to standardize biomarkers that have been validated and being adopted in the research community via an IEEE Working Group (P1752, Open Mobile Health Standards). To evaluate its work under realistic settings, CP7 is conducting multiple iterations of 100-day field studies in 100 participants in collaboration with the Open Humans project to generate open data set that can be used by researchers to develop mHealth biomarkers for detecting daily stressors.
CP7 will get access to novel biomarkers from TR&D3 Aim 1 so that it can develop and implement appropriate annotations, provenance, and pursue standardization. This step will enable the adoption of these biomarkers by the wider research community, especially among researchers working on secondary analysis of existing datasets. A particularly relevant category of metadata that CP7 is concerned with is that relating to privacy. These include metadata describing context-dependent privacy policy that govern downstream sharing and use of sensor measurements and derivative micromarkers and biomarkers. It also includes sharing of metadata capturing transformation (e.g. sanitization, addition of noise etc.) that data stream may have undergone due to upstream exercise of privacy policy so as to allow robust computation of biomarkers that discriminate between privacy related data quality degradation and data missingness or degradation due causes such as battery exhaustion, network connectivity outages, sensor detachments, and others. As the data collected in CP7 studies will be publicly available and capture large amounts of sensor data in daily life, CP7 offers a tremendous opportunity for bi-directional interaction with TR&D3’s research under Aim 3. On the one hand, the privacy mechanisms developed under TR&D3 Aim 3 will provide CP7 with concrete instances of privacy related transformation that the metadata framework must capture. On the other hand, the metadata framework in CP7 and its stressors studies provides a vehicle for the TR&D3 Aim 3’s methods and tools for privacy-utility tradeoff in biomarker computation to be evaluated at scale and made available to the community in the form of concrete implementation. The interaction with CP7 regarding metadata mechanisms will be an iterative push-pull, whereby the feedback from deployment of the mechanisms in the studies will be used to refine the privacy mechanisms under Aim 3, which in turn will be used by CP7 to refine the metadata framework and re-evaluated in a new iteration of the Open Humans study.
CP, Emotional Context, Stress, TR&D3
You must be logged in to post a comment.
No Comments